


Using CREATE TABLE AS SELECT (CTAS) SQL statements is a well established method of copying and transforming structured data.Trino’s inherent ability to manipulate data from many different sources, sinks and formats makes this a particularly effective way to move data between different storage systems and different storage formats.
Part 1 of this series provides the context for Trino’s role in Hive migration and in Part 2 we prepared a sandbox environment for exploring some of the migration challenges. In this we deployed two instances of Hive, HDFS and S3 storage and connected them together using Trino. If you’ve not already read Part 2 I would strongly suggest doing so as you’ll need a working sandbox environment if you want to follow along. You’ll need a working sandbox environment and a correctly configured SQL client to follow the examples in this post. As a quick recap, what you should have is a Stackable Data Platform cluster running two instances of Hive metastore, HDFS and S3 storage and Trino glueing it all together.

To start with, the sandbox is a blank canvas with the two Hive metastore instances there to simulate migration between a legacy Hive cluster and Stackable. The focus will be on using SQL queries in Trino to move data between clusters along with some basic data engineering with no further tooling required aside from Trino. You will find the code to accompany this post at https://github.com/stackabletech/hive_migration_blog.
Moving tables using CTAS
Using SQL and the CREATE TABLE AS SELECT (CTAS) pattern gives us a powerful yet relatively simple way to copy data and its associated table structure. In the case of Trino it’s even more useful since we can connect different databases and storage systems together, translating between platforms and data formats on the fly. To bootstrap our testing we will populate our Hive+HDFS cluster with some data for us to migrate using a special built-in Trino catalog that serves up the TPC-DS benchmark data set. The stack we installed previously in Part 2 has conveniently defined this catalog in the Stackable Trino configuration.
In the tutorial git repo you will find a file named sql/create_hive_tpcds.sql that contains the SQL statements to create the Hive schema and the TPC-DS tables. You can run this script using any compatible Trino client, the following example showing how to run this using the Trino CLI client.
trino --server https://localhost:8443 --user admin --insecure --catalog hivehdfs --schema default -f sql/create_hive_tpcds.sql
Here’s a quick breakdown of what this script does; it creates a new Trino schema (analogous to a database in Hive) named tpcds in the catalog hivehdfs. As with creating databases in Hive we specify the default storage location for the schema. In this instance we choose the HDFS service we’ve deployed in our sandbox.
create schema hivehdfs.tpcds
with (LOCATION = 'hdfs://hdfs/user/hive/warehouse/tpcds.db');
Stackable Data Platform gives us the ability to share configuration between services. Deploying the pre-configured stack automatically created the HDFS client configuration files core-site.xml and hdfs-site.xml and we made them available to Trino when we created the hivehdfs catalog and referencing the HDFS service in the catalog configuration. This means that we can use the HDFS service name “hdfs” to address our HDFS cluster as shown in the example above. Being able to define the relationships and dependencies between services in code is one of the reasons we can repeatedly and consistently deploy SDP in a dynamic environment like Kubernetes.
The remaining statements in the script create the tables using a CTAS statement, reading the data from the “tpcds” catalog. We’ll use Apache Parquet, a popular columnar data file format, to store the data on our HDFS cluster.
create table hivehdfs.tpcds.call_center
with (FORMAT = 'PARQUET')
as select * from tpcds.sf1.call_center;
We do this to create a Hive table for each of the tables found in the tpcds schema. In most cases we can simply perform a simple select * on the source table but occasionally we’ll encounter issues such as type incompatibility between different databases. Trino provides useful error messages when it encounters problems such as these, which will be displayed in both the SQL client output and on the web UI, which should be accessible on your sandbox cluster at https://localhost:8443/ui/.
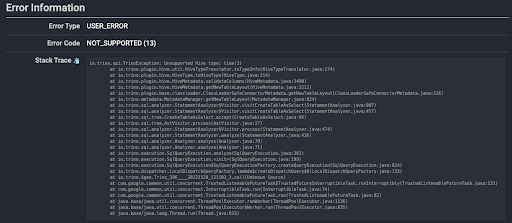
This is especially useful when you’re testing migration of your own data. Trino often removes the need for other ETL tools when using CTAS since it understands and can translate between many different data sources and formats. In this case we see that Hive doesn’t support the “time” data type that appears in the source table dbgen_version, so in the DDL query for this table I cast this value to a varchar type instead.
create table hivehdfs.tpcds.dbgen_version
with (FORMAT = 'PARQUET')
as select
dv_version,
dv_create_date,
cast(dv_create_time as varchar) as dv_create_time,
dv_cmdline_args
from tpcds.sf1.dbgen_version;
If the script ran successfully you will now have a Hive database containing a copy of all the tables from the tpcds schema stored on HDFS in Parquet format.
With our source Hive database created we will again use CTAS to copy data from the Hive 2 on HDFS schema into Hive 3 on S3. Just for fun we’ll transform the data from Parquet to Apache ORC format; perhaps we want ACID support that Parquet does not provide. As before the SQL to perform this action has already been prepared and can be found in the accompanying Git repo.
trino --server https://localhost:8443 --user admin --insecure --catalog hives3 --schema default -f sql/hive_s3_ctas.sql
Transforming data in this way is common on Hive clusters, here Trino lets us do this while at the same time shifting the data to a different cluster.
Federated queries across data sources
As well as being able to move data between different sources and sinks we can also run SQL queries across them. Trino reads the data into the worker nodes and executes the query there, meaning cross database queries become a reality. You can even write to a completely different sink database, ideal for publishing data sets to data marts outside of your data platform.
Following this theme we’ll run a federated query across both of the Hive databases to produce a report and store the results in a new table. I’ve prepared another SQL script with the required statements to do this.
trino --server https://localhost:8443 --user admin --insecure -f sql/cross_hive_join.sql
Again breaking down the contents of the script we’ll start by creating a new schema to store the table.
create schema if not exists hives3.tps_reports
with (LOCATION = 's3a://demo/tps_reports.db');
We have the same data set in both Hive databases, but let’s for a moment imagine that our customer address database is in a separate system to our preferred customer loyalty scheme. We will run a query across joining tables across both Hive installations and generate a report on how many customers are opted into the loyalty program per state. This data we’ll store in a new table in the scheme we just created.
create table hives3.tps_reports.loyalty_by_state as
select
coalesce(ca.ca_state, 'STATE_UNKNOWN') as state,
coalesce(c.c_preferred_cust_flag, 'PREFERRED_STATUS_UNKNOWN') as preferred,
count(*) as "count"
from hives3.tpcds.customer_address ca
join hivehdfs.tpcds.customer c
on ca_address_id = c_customer_id
group by ca_state, c_preferred_cust_flag;
Now if we query the new table we’ll see the customer status grouped by state.
select * from hives3.tps_reports.loyalty_by_state
order by state, preferred;
state |preferred |count|
-------------+------------------------+-----+
AK |N | 177|
AK |PREFERRED_STATUS_UNKNOWN| 20|
AK |Y | 168|
AL |N | 505|
AL |PREFERRED_STATUS_UNKNOWN| 39|
AL |Y | 466|
AR |N | 553|
AR |PREFERRED_STATUS_UNKNOWN| 38|
AR |Y | 549|
There is of course no reason why this would have to be stored in Hive as per this example and any of the Trino connectors that support write operations could be used. We could just as easily have stored the report in a relational database, in delta lake or an object store like S3, meaning we can feed other platforms with data while avoiding the need for direct access to the big data platform and all the risks inherent to that.
Raising your storage format game
When you decide to move away from a data platform like Hive there is the opportunity to gain the benefits of new products and features that have come along since its installation. Apache Iceberg was designed to address many of the issues that faced Hive users and allow for building better big data warehouses that work across multiple technologies. Trino supports Iceberg, using Hive metastore to store table metadata.
Let’s get some data in an Iceberg table. We start as before by creating a schema by running the script sql/iceberg.sql. This time we’ll be creating tables in the catalog named ‘iceberg’ that was created when we installed the Stackable demo.
trino --server https://localhost:8443 --user admin --insecure -f sql/iceberg.sql
It starts by creating a new schema in the ‘iceberg’ catalog.
create schema if not exists iceberg.iceberg_test
with (LOCATION = 's3a://demo/iceberg_test.db');
The data types supported by Iceberg differ from Hive and notably in the case of our TPC-DS test data Iceberg does not support the CHAR() format that appears in many of the tables. If we try to do a simple CTAS operation using SELECT * we will run into an error like we did earlier. This means the SQL to create our Iceberg tables will have to cast many of the fields to a supported data type. In this case varchar seems like a reasonable choice.
create table if not exists iceberg.iceberg_test.call_center
with (FORMAT = 'PARQUET')
as select
cc_call_center_sk,
cast(cc_call_center_id as varchar(16)) as cc_call_center_id,
cc_rec_start_date,
cc_rec_end_date,
cc_closed_date_sk,
cc_open_date_sk,
cc_name,
cc_class,
cc_employees,
cc_sq_ft,
cast(cc_hours as varchar(20)) as cc_hours,
cc_manager,
cc_mkt_id,
cast(cc_mkt_class as varchar(50)) as cc_mkt_class,
cc_mkt_desc,
cc_market_manager,
cc_division,
cc_division_name,
cc_company,
cast(cc_company_name as varchar(50)) as cc_company_name,
cast(cc_street_number as varchar(10)) as cc_street_number,
cc_street_name,
cast(cc_street_type as varchar(15)) as cc_street_type,
cast(cc_suite_number as varchar(10)) as cc_suite_number,
cc_city,
cc_county,
cast(cc_state as varchar(2)) as cc_state,
cast(cc_zip as varchar(10)) as cc_zip,
cc_country,
cc_gmt_offset,
Cc_tax_percentage
from hivehdfs.tpcds.call_center;
This does highlight some of the drawbacks of using CTAS statements and you’ll find if you dig under the covers a lot of ETL tools do this or something very similar, with rule-based type translation being used to address these type alignment issues.
OK, so now we have some Iceberg tables. What next? One big difference between Iceberg compared with traditional Hive tables is the ability to update data and avoid the write-once, read-many paradigm that is so strongly associated with Hadoop. Let’s close one of the call centers by updating the field cc_rec_end_date. We’ll check the current record status first.
select cc_call_center_id, cc_rec_start_date, cc_rec_end_date
from iceberg.iceberg_test.call_center where cc_call_center_sk = 3;
|cc_call_center_id|cc_rec_start_date|cc_rec_end_date|
+-----------------+-----------------+---------------+
|AAAAAAAACAAAAAAA | 2001-01-01| |
Then we will update the record and check it once more.
update iceberg.iceberg_test.call_center
set cc_rec_end_date = cast('2022-12-01' as date)
where cc_call_center_sk = 3;
select cc_call_center_id, cc_rec_start_date, cc_rec_end_date
from iceberg.iceberg_test.call_center where cc_call_center_sk = 3;
|cc_call_center_id|cc_rec_start_date|cc_rec_end_date|
+-----------------+-----------------+---------------+
|AAAAAAAACAAAAAAA | 2001-01-01| 2022-12-01|
Connectors sharing a single Hive metastore
When we defined the Hive on S3 and Iceberg catalogs we pointed them at the same Hive metastore. This presents a challenge since the Hive connector cannot read Iceberg tables and vice versa and yet if we list the contents of each catalogue we will see the same schemas and tables. With a clever bit of configuration we can solve this using the table redirect feature to add a cross reference between each of the catalogs.
---
apiVersion: trino.stackable.tech/v1alpha1
kind: TrinoCatalog
metadata:
name: hives3
# ...
configOverrides:
hive.iceberg-catalog-name: iceberg
---
apiVersion: trino.stackable.tech/v1alpha1
kind: TrinoCatalog
metadata:
name: iceberg
…
configOverrides:
iceberg.hive-catalog-name: hives3
Reading a table from either of the catalog it will automatically redirect the request to the correct catalog. Overall this is a much better way to present the data as it avoids having to run an additional Hive metastore for each table type.
The End?
We’ve reached the conclusion of this series of posts on Hive and Trino but far from the end of the Hive migration journey. The process of migration has many moving parts and I’ve shown some of the unique features of Trino in handling many different connectors for structured data and how they can play well together. Crucially I’ve shown how Stackable can make it easier to deploy your own data stack and to integrate it with components both within and beyond Stackable Data Platform. Even if you’re not a Hive user, the tools and techniques in the blog posts are useful if you just want to try out Trino or want to build out a modern data stack for your organisation.