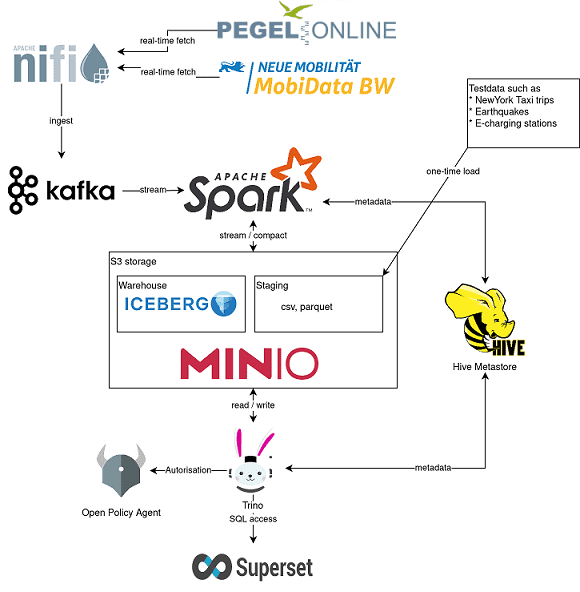
Facilitates ingestion, data flow management and automated data exchange between systems.
- Easy Data Routing and Transformation: Offers a user-friendly interface for data flow management, supporting rapid design and deployment of processing pipelines.
- System Integration: Connects to a variety of data sources and sinks, facilitating data ingestion from disparate systems.
- Data Lineage: Tracks data flow from source to destination, enhancing auditing and compliance.
- Flexibility: Customizable processors and the ability to handle various data formats and sizes.
Streamlining Data Workflows with precision and scalability.
- Advanced Workflow Orchestration: Apache Airflow provides comprehensive workflow planning and management that enables precise control of data processing tasks within the Stackable Data Platform.
- Dynamic Pipeline Creation: Easily define, schedule, and monitor complex data pipelines using Airflow’s intuitive UI and powerful programming framework. Customize your workflows to match your data processing needs perfectly.
- Scalable and Reliable: Airflow can be easily scaled. Simultaneous workflows can be handled effortlessly so that data tasks are executed reliably regardless of volume.
- Efficient monitoring and logging: Airflow’s monitoring functions enable quick identification and resolution of problems and ensure smooth data operation.
Offers powerful data processing capabilities, enabling distributed analytics and machine learning on large data sets.
- In-Memory Computing: Accelerates processing speeds by keeping data in RAM, significantly faster than disk-based alternatives.
- Advanced Analytics: Supports complex algorithms for machine learning, graph processing, and more.
- Fault Tolerance: Resilient distributed datasets (RDDs) provide fault tolerance through lineage information.
- Language Support: Offers APIs in Python, Java, Scala, and R, broadening its accessibility and usability.
Enables (virtualized) data access across different data sources and improves the flexibility and speed of queries in data architectures.
- Flexible Table Formats: Supporting Apache Iceberg and Delta Lake.
- Fast Query Processing: Engineered for high-speed data querying across distributed data sources.
- Federated Queries: Allows querying data from multiple sources, simplifying analytics across disparate data stores (data federation).
- Scalable and Flexible: Easily scales to accommodate large datasets and complex queries.
- User-Friendly: Supports SQL for querying, making it easily accessible to users familiar with relational databases.
Stackable enhances its dedication to open and flexible data solutions by incorporating two premier table formats: Apache Iceberg and Delta Lake. Our customers can therefore choose the best option for their specific requirements. Below, we outline key factors to consider when choosing between Delta Lake and Apache Iceberg. However, we always recommend carrying out tests with real use cases in order to be able to make the most accurate decision possible.
Apache Iceberg:
- Ideal if particular emphasis is placed on user-friendliness and cross-platform compatibility.
- Supports continuous schema evolution and the analysis of large data periods.
- Its efficiency in query performance makes it a superior option for data warehousing needs.
Delta Lake:
- Perfectly aligns with users already utilizing Delta Lake architectures.
- Exceptionally suitable for setups that demand ACID transactions and strong data integrity.
- Unparalleled in environments where high data integrity is critical.
Integrating advanced data governance and fine-grained access control into the data lakehouse.
- Unified Policy Framework: OPA provides a powerful, unified framework for governing access across the entire data lakehouse, ensuring consistent enforcement of security policies, data privacy regulations, and compliance requirements.
- Declarative Policy as Code: Implement governance policies declaratively using Rego, OPA’s high-level language. This approach allows for the development of clear, understandable policies that can be version-controlled, reviewed, and deployed as part of your CI/CD pipeline.
- Fine-Grained Access Control: Achieve granular control over data access and manipulation within the data lakehouse architecture.
- Scalable and High-Performance: OPA also supports large, complex data environments and ensures that governance policies are evaluated efficiently without compromising access to data or application performance.