
Introduction
At Stackable, we like to push the limits of what our Stackable Data Platform can do. Whether it’s the millisecond performance of HBase on Kubernetes (https://stackable.tech/en/hbase-performance-benchmark/) or connecting to legacy databases via Hive (https://stackable.tech/en/stackable-and-trino-part-3-migrating-hive-tables-using-ctas/).
This time we focused on modern data integration. And while Stackable already offers several possibilities for ELT/ETL, e.g. with support for Apache NiFi and Apache Spark™, we also investigated how data integration is possible with other data transformation tools like the well-known dbt.
TLDR, it is easily possible!
The boilerplate we developed works, and like everything from Stackable, it is easy to set up and easy to integrate. Below is some background, otherwise go directly to https://github.com/stackabletech/dbt-trino-stackable to try it out for yourself.
Architecture
In this showcase, we present a modern data lakehouse architecture using dbt-Trino and Apache Iceberg within the Stackable Data Platform, leveraging the famous TPC-H dataset. The architecture is designed using the medallion architecture design pattern with three layers – bronze, silver, and gold – each representing a level of data processing and refinement.

Three-Layered Approach Medallion Architecture for Data Lakehouses
We applied a very basic form of the medallion architecture pattern to achieve a clear distinction within the data lakehouse. It consists of these layers:
- Bronze Layer – The Raw Data Foundation: This initial layer focuses on ingesting raw data from the TPC-H dataset into the Stackable Data Platform using Apache Iceberg as a table format. The data is stored in S3 in its most unaltered, pure form. This layer is essential for maintaining the original state and integrity of the data, providing a reliable foundation for all future transformations and analysis. Typically, it’s also where the initial exploration and understanding of the data’s structure and quality begins, setting the stage for further processing.
- Silver layer – Data processing and refinement hub: Here, data is transformed from its raw state into a more polished and usable form. This transformation is typically achieved through a series of cleansing, normalization, and pre-analytics processing steps. The layer acts as a crucible where data is also enriched and aligned with specific business rules and analytic models. It is a dynamic space where data begins to take shape, becoming more relevant and meaningful to business applications. This layer represents a critical stage in the data lifecycle, bridging the gap between raw data collection and advanced analytics.
- Gold Layer – The pinnacle of data analysis: The Gold layer is where data reaches its final state of refinement and readiness for high-level analysis and business decision-making. In this layer, data is fully optimized for querying, ensuring that it is not only accessible, but also highly performant for analytical operations. This optimization can include advanced indexing, partitioning, and formatting tailored to support fast, efficient read operations. The Gold layer is characterized by its focus on delivering data that is not only usable, but also strategically insightful. It is the layer where data is transformed into a valuable asset that drives business intelligence and facilitates informed strategic decisions.
Implementation
Running the dbt pipeline transforms a subset of the TPC-H dataset from the bronze layer to the gold layer, creating the data foundation for further analysis, data science, or reporting (with Stackable, you could easily add Apache Superset to the mix…).
The final lineage graph looks like this:
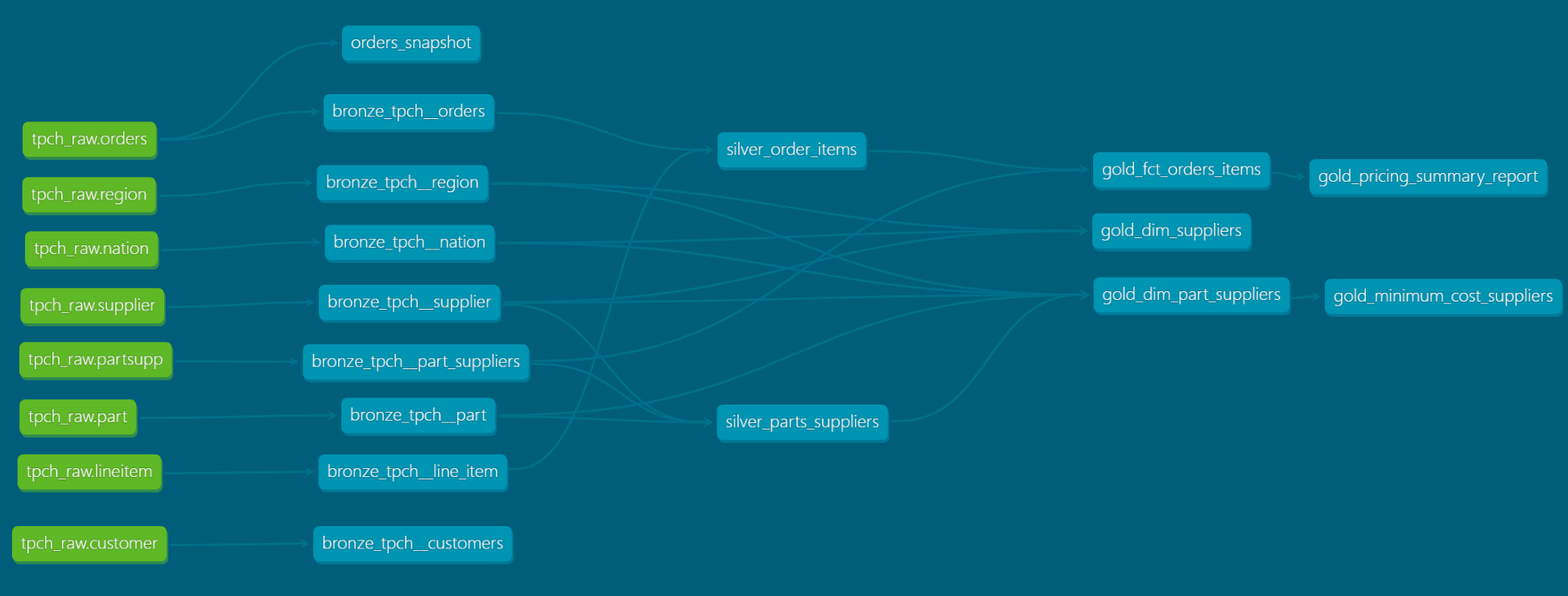
Benefits of This Setup
This showcase provides several key benefits that are critical to modern data architectures:
- Open Source Tooling: Stackable’s use of open source technologies such as Trino, Iceberg, and dbt provides transparency, flexibility, and community-driven innovation. It allows for customization and continuous improvement.
- Cloud-agnostic framework: The cloud-agnostic nature of the Stackable Data Platform running on Kubernetes ensures flexibility in deployment, whether on-premises, across different cloud providers, or on your workstation, avoiding vendor lock-in.
- Scalability and Performance: The integrated approach of decoupling storage and compute with Trino and Iceberg ensures scalability and high performance, which are critical for efficiently handling large data sets.
- Data Quality and Consistency: The layered architecture provides a structured foundation for data cleansing and normalization, ensuring high data quality and consistency for reliable analytics.
- Cost-Effectiveness: The use of open source tools provides a cost-effective alternative to proprietary solutions, ideal for organizations looking to optimize their data analytics budgets.
- Easy integration with existing tools: Compatibility with multiple tools and platforms (such as dbt or S3 storage in this example) facilitates seamless integration into existing IT ecosystems, improving workflow continuity and leveraging existing data tool investments.
Conclusion and Outlook
The approach presented here, with Stackable and dbt, provides a dynamic and scalable boilerplate for data management. The three-tier architecture, from raw data to refined analytics, embodies efficiency, reliability, and flexibility, making it an exemplary model for today’s data-driven enterprise.
In particular, with the addition of Stackable’s OPA (Open Policy Agent), this open source foundation can be easily enhanced for security and governance, supporting fine-grained access control and regulatory compliance.
In addition, rich data analytics could easily be added with tools such as Jupyterhub or Apache Superset.