


Demos


Demos

Possible uses of the Stackable Data Platform
The following data stack application examples demonstrate how easily and flexibly the Stackable Data Platform can be used for very different use cases. All demos deliberately focus on one topic at a time and:
- use stackablectl to install
- can be set up 1:1 on your environment
- demonstrate contexts step by step
- are available as open source code in Github
Demo: argo-cd-git-ops
GitOps in action with ArgoCD
This demo showcases how to deploy and manage the Stackable Data Platform using ArgoCD and GitOps principles. By storing your cluster’s desired state in Git, you ensure that every change is version-controlled, auditable, and automatically synchronized to your Kubernetes environment.
Key Features:
- GitOps Workflow: Deploy and update Stackable operators and products declaratively via Git-managed manifests.
- Automated Sync: Changes committed to Git are automatically applied to your cluster by ArgoCD.
- Sealed Secrets: Securely manage sensitive credentials in Git using Bitnami’s Sealed Secrets.
- Airflow Integration example: Update Airflow DAGs and configurations simply by committing changes to your repository.
- Multi-Environment Support: Easily extend deployments across development, staging, and production environments.
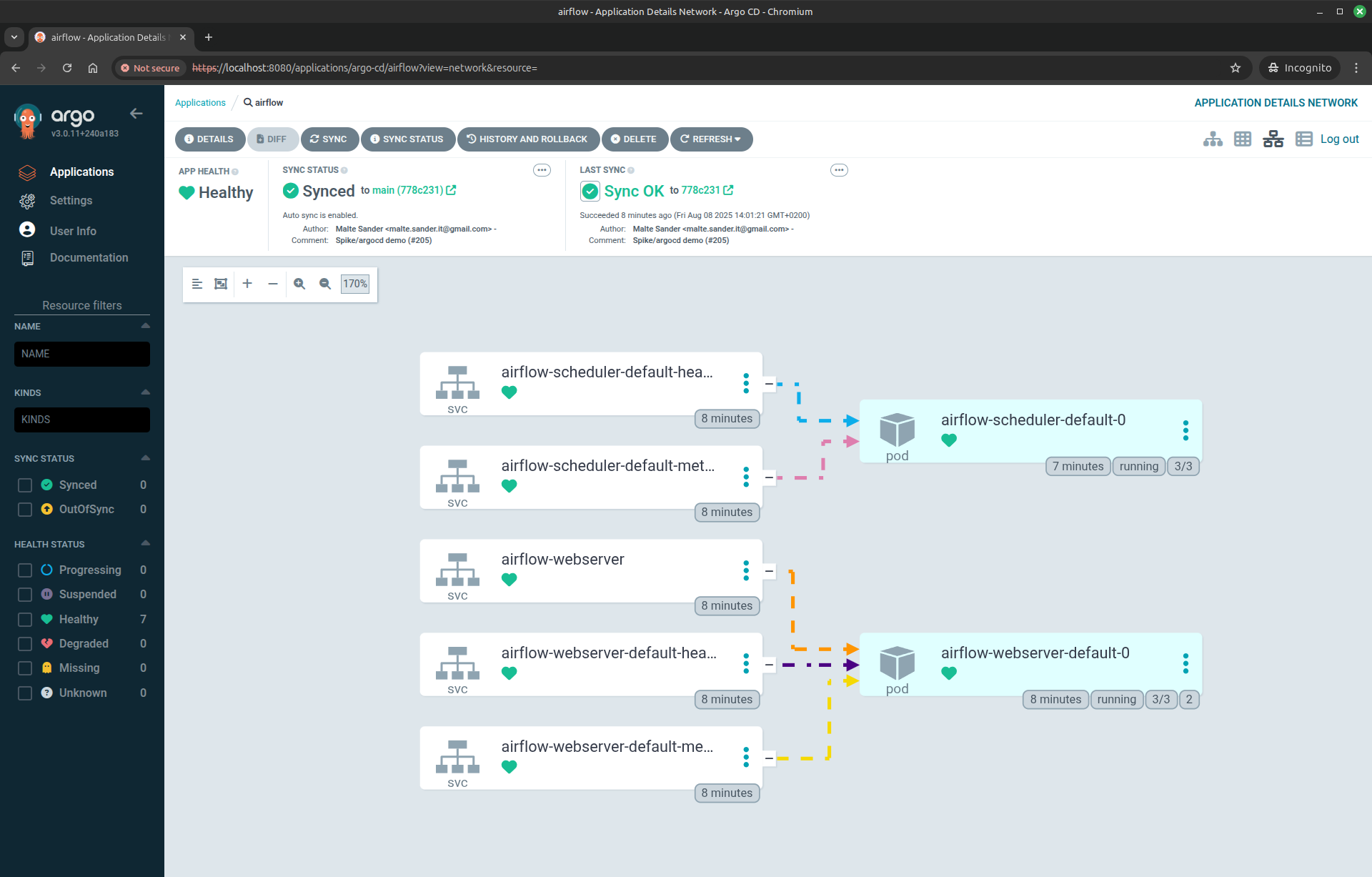
Demo Components:
- ArgoCD: A declarative, GitOps continuous delivery tool for Kubernetes.
- Airflow: A platform to programmatically author, schedule, and monitor workflows, with DAGs synced from Git.
- MinIO: S3-compatible storage for Airflow logs and data, ensuring persistence and accessibility.
- Stackable Operators: Deploy and manage data products like Apache Spark, Trino, and Kafka using Stackable’s Kubernetes operators.
Demo Workflow:
- Installation: Deploy the demo on your Kubernetes cluster with a single command, bootstrapping ArgoCD and all required operators.
- Accessing ArgoCD: Log in to the ArgoCD web UI to monitor the synchronization of your Git repository with the cluster state.
- Git Integration: Fork the demo repository, make changes to manifests or DAGs, and watch ArgoCD automatically apply updates to your cluster.
- Interacting with Airflow: Use the Airflow web interface to trigger and monitor workflows, with logs stored in MinIO/S3.
This demo provides a scalable, auditable, and automated approach to managing your data platform. It serves as a blueprint for implementing GitOps in production, reducing manual operations and improving consistency. For detailed instructions and customization, refer to the demo documentation.
HOW-TO start,
within a Kubernetes-Cluster
Option 1 – exploratory:
stackablectl demo install argo-cd-git-ops –namespace argo-cd
Option 2 – interactive:
stackablectl demo install argo-cd-git-ops –namespace argo-cd –parameters customGitUrl=<my-demo-fork-url> –parameters customGitBranch=<my-custom-branch-with-changes>
Demo: jupyterhub-keycloak
Stackable and JupyterHub
This demo showcases a comprehensive multi-user data science environment on Kubernetes, integrating the Stackable Data Platform with JupyterHub and Keycloak for robust user authentication and identity management.
Key Features:
- Authentication for JupyterHub: Utilizes Keycloak for managing user access, ensuring secure and manageable authentication processes.
- Dynamic Spark Integration: Demonstrates the ability to start a distributed Spark cluster directly from a Jupyter notebook, with dynamic resource allocation tailored to user needs.
- S3 Storage Interaction: Illustrates reading from and writing to an S3-compatible storage (MinIO) using Spark, with secure credential management through Kubernetes secrets.
- Scalable and Flexible: Leverages Kubernetes for scalable resource management, allowing users to select from predefined resource profiles based on their requirements.
- User-Friendly Interface: Provides an intuitive environment for data scientists to easily handle common data operations.
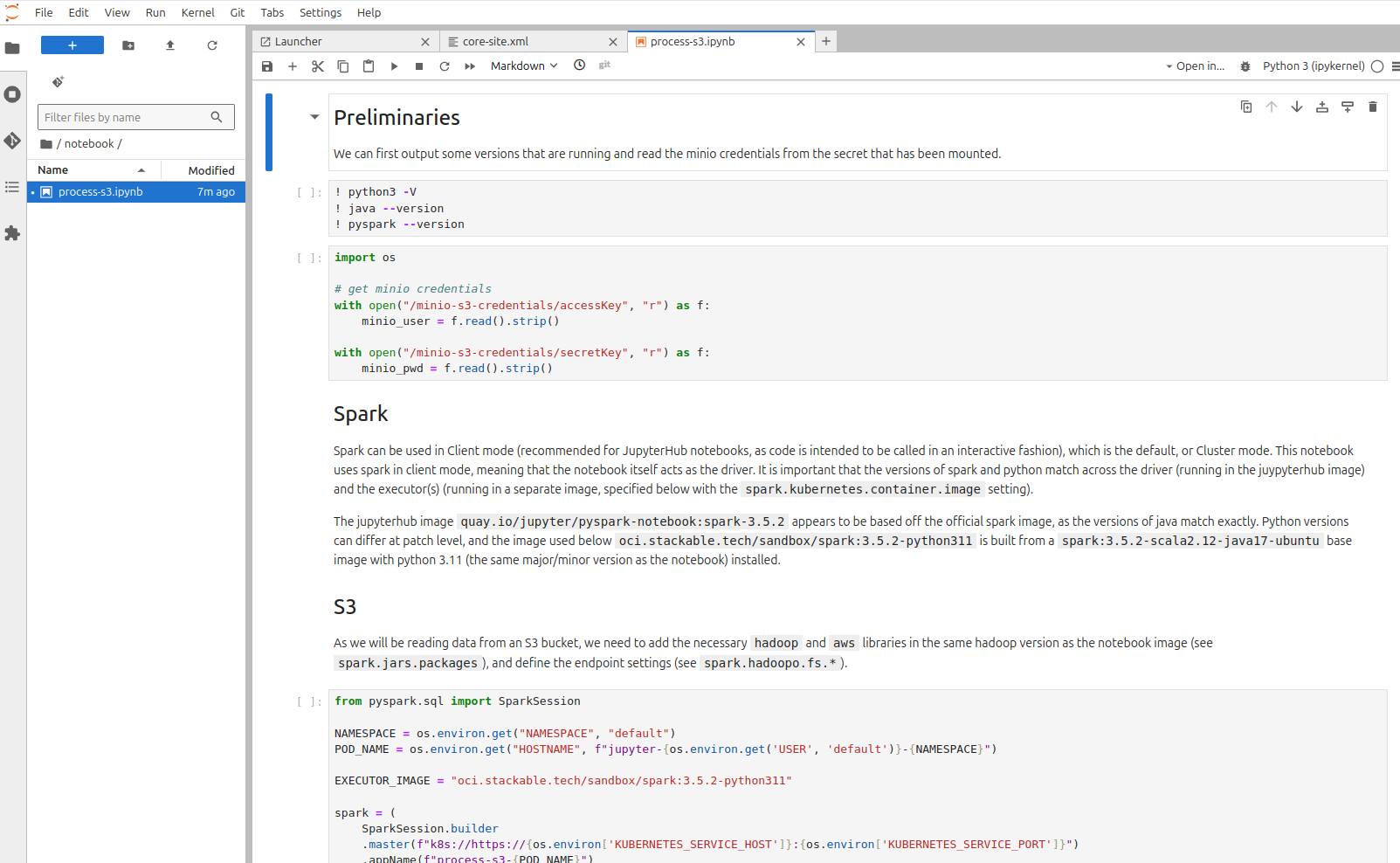
Demo Components:
- JupyterHub: A multi-user server for Jupyter notebooks, enabling collaborative data analysis and processing.
- Keycloak: An identity and access management solution that handles user authentication and authorization.
- MinIO: An S3-compatible storage solution for storing and retrieving data securely.
- Apache Spark: A unified analytics engine for large-scale data processing, configured to run in client mode with dynamic executor management.
Demo Workflow:
- Installation: The demo is installed on an existing Kubernetes cluster using a simple command, also setting up all necessary operators and data products.
- Accessing JupyterHub: Users navigate to the JupyterHub web interface and log in using predefined credentials, authenticated via Keycloak.
- Data Processing: Users can select a notebook profile and start processing data using the provided notebooks, which demonstrate various data operations against S3 storage.
- Multi-User Environment: The demo supports multiple concurrent users, each with their own isolated environment for data processing tasks.
This demo provides a robust template for data scientists to build complex data operations in a secure and scalable environment. For further details and customization options, refer to the demo notebook and configuration files referenced in the documentation.
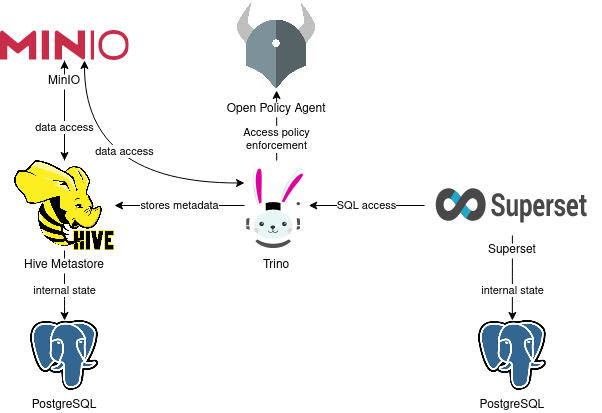
Demo: end-to-end-security
Integrated Data Security
This technology demo showcases some of Stackable’s latest features, focusing on end-to-end security:
It shows how single sign-on works across the platform and how impersonation allows for separation of access to the underlying data. It also demonstrates advanced use cases such as row-level security and data masking for critical data.
The demo uses a data lakehouse schema extract of TPC-DS, a decision support benchmark, illustrating the platform’s robust analytics capabilities.
Technologically, elements of previous demos are included, such as:
- HDFS w/ Iceberg: The Hadoop Distributed File System, used for scalable and reliable storage of large volumes of data. Configured to use Apache Iceberg as table format.
- Hive: A data warehouse infrastructure built on top of Hadoop, allowing for data summarization, querying, and analysis.
- Trino: A fast distributed SQL engine for interactive analytics. It provides powerful SQL querying capabilities over large datasets.
- Open Policy Agent (OPA): A general-purpose policy engine that provides fine-grained control and unified policy enforcement across various Stackable data apps.
- Superset: A modern data exploration and visualization platform, enabling intuitive data insights.
- Spark: A unified analytics engine for large-scale data processing, used here to perform data engineering, data science, and machine learning.
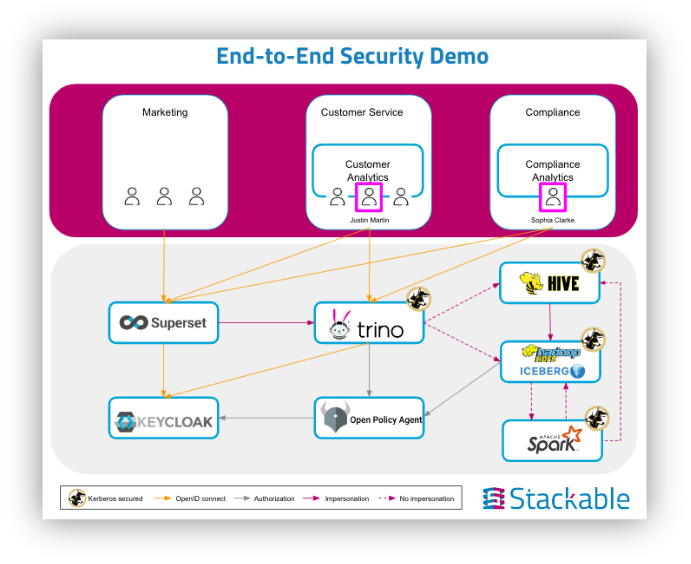
Additionally, the demo shows new security components:
- Kerberos: A network authentication protocol designed to provide strong authentication for client-server applications using secret-key cryptography, now running on Kubernetes for secure authentication.
- Rego rules: The policy language for OPA, allowing the creation of complex policy decisions for fine-grained access control.
- OpenID Connect (OIDC): A simple identity layer on top of the OAuth 2.0 protocol, allowing clients to verify the identity of users and obtain their profile information securely.
- Keycloak: in addition to the Stackable Data Platform – an open-source identity and access management solution. It handles user authentication, authorization, and provides single sign-on (SSO) across various applications.
The result is a powerful and secure template created for the fictitious “knab” organization for a modern data stack with the Stackable Data Platform.
Demo: data-lakehouse-iceberg-trino-spark
Data Lakehouse technology showcase
This technology demo showcases some of Stackable’s latest features.
The demo contains elements of previous demos i.e.
- real-time event streaming with Apache NiFi
- Trino for SQL access and
- visual data display and analysis with Apache Superset
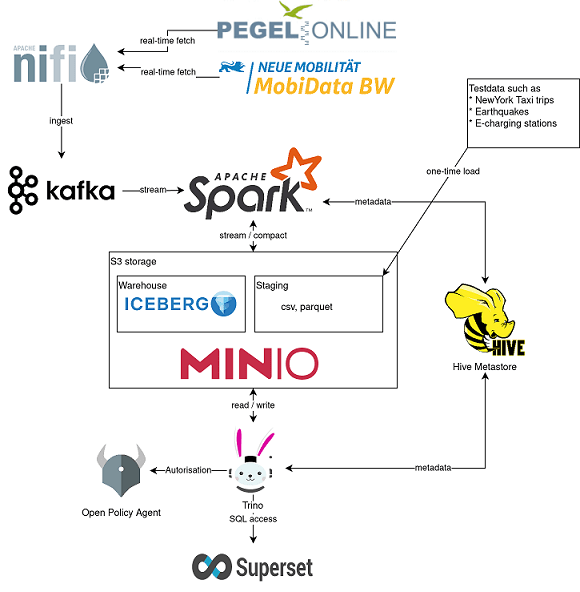
But, adding to this, the demo also includes new lakehouse features such as the integration with Apache Iceberg providing e.g. transactional consistency and full schema evolution.
The result is a powerful blueprint for a modern data stack with the Stackable Data Platform.
Other highlights of the demo:
- Apache Spark: A multi-language engine for executing data engineering, data science, and machine learning. This demo uses it to stream data from Kafka into the lakehouse.
- Open policy agent (OPA): An open source, general-purpose policy engine that unifies policy enforcement across the stack. This demo uses it as the authorizer for Trino, which decides which user is able to query which data.
HOW-TO start,
within a Kubernetes-Cluster:
stackablectl demo install data-lakehouse-iceberg-trino-spark
(note: tested on 10x4core nodes with each 20GB RAM and 30GB HDD, persistent volumes with a total size of approximately 1TB)
Note: if you are looking for a smaller setup, please take a look at our trino-iceberg demo:
stackablectl demo install trino-iceberg
Demo: SPARK-K8S-ANOMALY-DETECTION-TAXI-DATA
Machine Learning for outlier detection
This Stackable Data Platform demo is an extension of the original TRINO-TAXI-DATA demo with Apache Spark™.
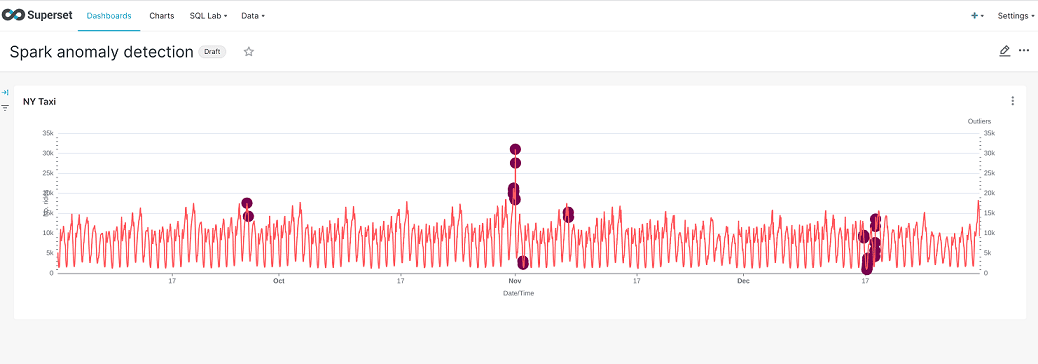
An often neglected factor when using data for machine learning is data quality. False measurements, missing values and the like distort the subsequent prediction quality. In certain scenarios, spikes, outliers, or other anomalies in the data are also relevant, in that they can form a basis for defining alerts.
Thus, the detection of outliers makes an important contribution to the successful use of data. Nowadays, science and industry use a variety of procedures and methods for this purpose.
In this demo, outlier detection is exemplified using Apache Spark by running an isolation forest algorithm on the data. The isolation forest algorithm is used for unsupervised model training, which means that the model does not require labeling.
Results of the detection are stored in Apache Iceberg format and visualized using Apache Superset.
HOW-TO start,
within a Kubernetes-Cluster:
stackablectl demo install spark-k8s-anomaly-detection-taxi-data
Demo: NIFI-kafka-druid-water-level-data
Real-time display of water levels
Low water or danger of flooding – the water levels of our rivers have moved into the public interest in times of climate change.
Our Stackable Data Platform demo shows the water levels of rivers in near real-time for Germany based on data from Pegel Online.
Several components of the Stackable Data Platform play together without requiring much configuration effort:
Apache Nifi and Kafka are used to fetch water level measurements from gauging stations distributed across Germany via an API from Pegel Online and store them in Apache Druid.
Druid is a scalable real-time database that can be queried using SQL. This method is used in the demo to query gauge levels via Apache Superset and visualize them in the dashboard. For permanent storage, Druid requires a so-called “deep storage”, which is implemented in our example via MinIO as an S3-compatible object store, as it is available in most public and private cloud environments.
HOW-TO start,
within a Kubernetes-Cluster:
stackablectl demo install nifi-kafka-druid-water-level-data
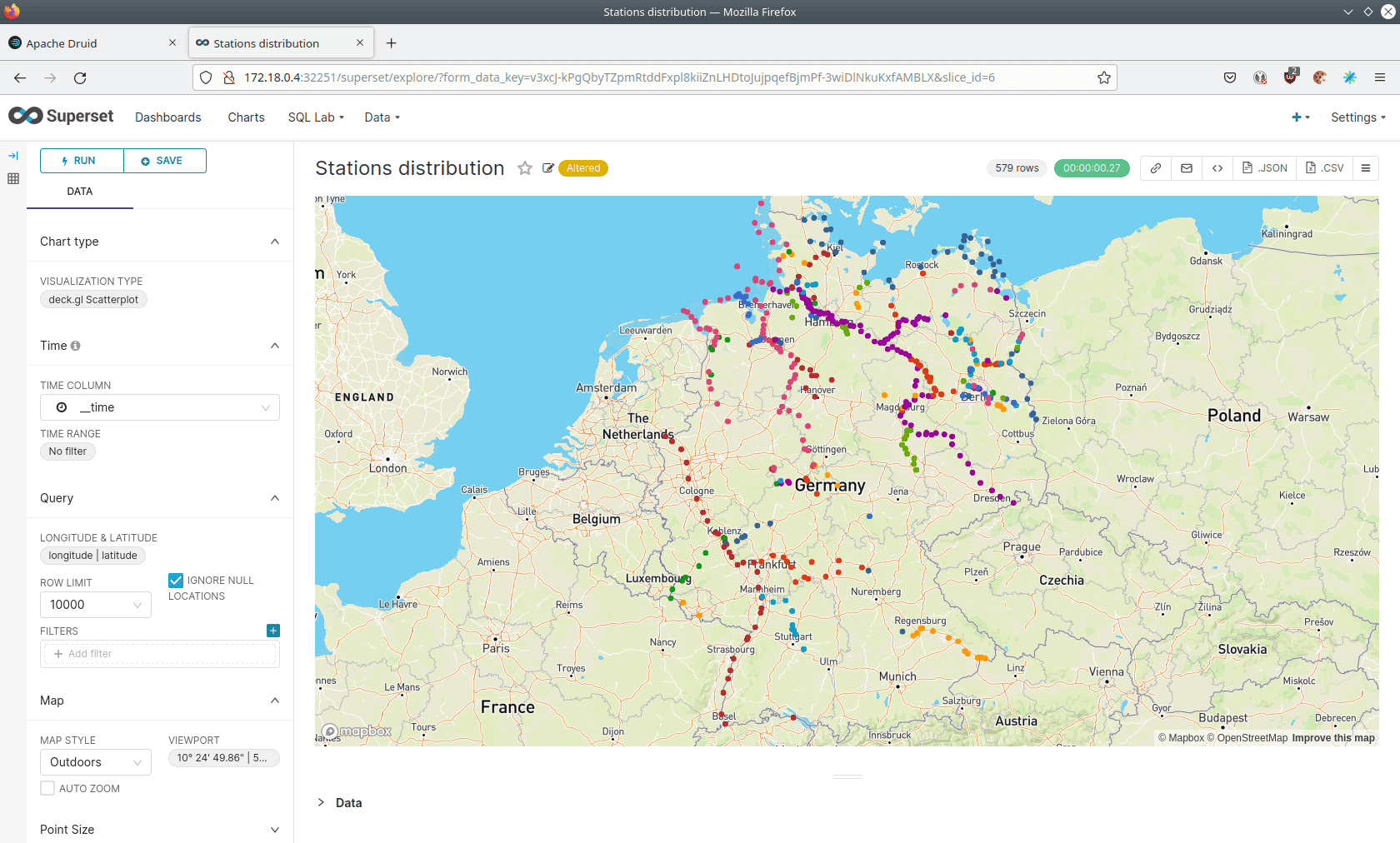
Demo: trino-taxi-data
Analysis with a data lake
Our Stackable operators are used to configure and roll out various components. In particular, this example shows how role-based data access can be implemented using the Open Policy Agent:
- MinIO, an S3-compatible object store, persistently stores the data for this demo.
- Hive-Metastore stores the metadata necessary to make the sample data accessible via SQL and is used by Trino in our example.
- Trino is our extremely fast, distributed SQL query engine for Big Data analytics that can be used to explore data spaces and that we use in the demo to provide SQL access to the data.
- Finally, Apache Superset we use to retrieve data from Trino via SQL queries and build dashboards on that data.
- Open Policy Agent (OPA): an open source, universal policy engine that unifies policy enforcement across the stack. In this demo, OPA authorizes which user can query which data.
Demo: NIFI-kafka-druid-earthquake-data
Event streaming of earthquake data
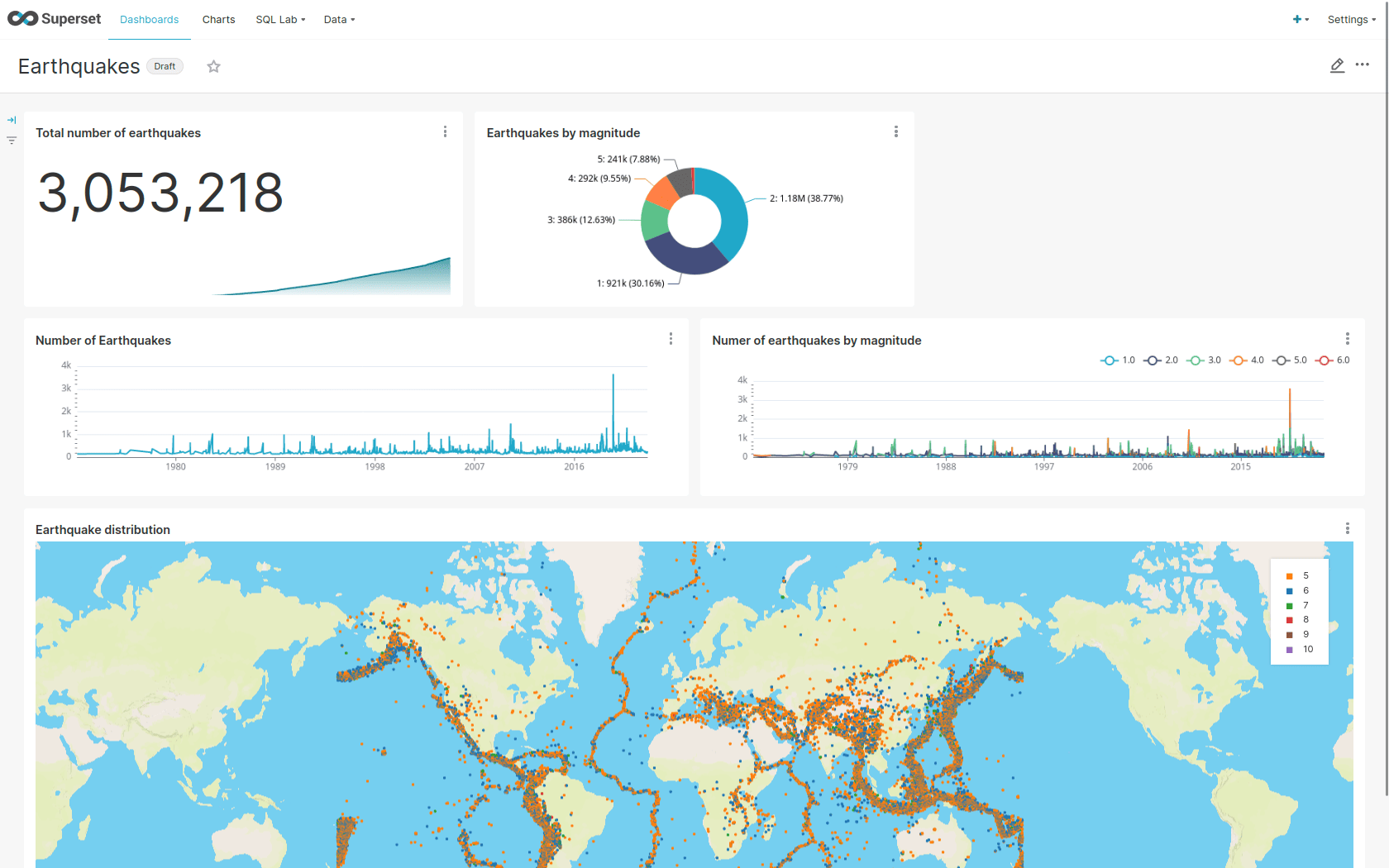
It includes the following operators:
- Apache Superset: a modern platform for data exploration and visualization. This demo uses Superset to retrieve data from Druid via SQL queries and build dashboards on that data.
- Apache Kafka®: A distributed event streaming platform for high-performance data pipelines, streaming analytics, and data integration. In this demo, Kafka is used as an event streaming platform to stream data in near real-time.
Apache Nifi: An easy-to-use, powerful system to process and distribute data. This demos uses it to fetch earthquake-data from the internet and ingest it into Kafka.
- Apache Druid: A real-time database to support modern analytics applications. This demo uses Druid to ingest and store data in near real-time from Kafka and provide access to the data via SQL.
- MinIO: An S3-compatible object store. In this demo, it is used as persistent storage for Druid to store all streamed data.
HOW-TO start,
within a Kubernetes-Cluster:
stackablectl demo install nifi-kafka-druid-earthquake-data
You have questions or remarks?
Need more Info?
Contact Sönke Liebau to get in touch with us:

Sönke Liebau
CPO & CO-FOUNDER of Stackable
Subscribe to our Newsletter
With the Stackable newsletter, you’ll always stay up to date on the latest from Stackable!


Newsletter
Subscribe to the newsletter
With the Stackable newsletter you’ll always be up to date when it comes to updates around Stackable!