


Demos


Demos

Einsatzmöglichkeiten der Stackable Data Platform
Die nachfolgenden Anwendungsbeispiele demonstrieren, wie einfach und flexibel sich die Stackable Data Platform für sehr unterschiedliche Anwendungsfälle einsetzen lässt. Alle Demos fokussieren bewusst auf jeweils ein Themengebiet und:
- nutzen stackablectl zur Installation
- lassen sich 1:1 bei Dir aufsetzen
- demonstrieren Zusammenhänge schrittweise
- sind als Open Source Code in Github verfügbar
Highlights:
Demo: OpenSearch RAG
Retrieval Augmented Generation mit OpenSearch
Diese Demo zeigt eine RAG-Pipeline (Retrieval Augmented Generation), die Antworten von Large Language Models auf eine konkrete Wissensbasis stützt – mithilfe von semantischer Suche, vollständig auf Kubernetes, ohne GPU-Anforderungen.
Highlights:
- Hybride OpenSearch-Suche: Kombiniert k-NN-Vektorähnlichkeit mit BM25-Keyword-Matching für eine überlegene Treffergenauigkeit gegenüber beiden Einzelansätzen.
- Lokale LLM-Inferenz: Llama 3.1 8B läuft vollständig im Cluster über Ollama – keine externen API-Aufrufe, keine Daten verlassen die Umgebung.
- 768-dim-Embeddings: Nutzt nomic-embed-text für quelloffene, hochperformante Dense-Retrieval-Embeddings, vorgeladen aus der Stackable-Dokumentation.
- Interaktives Notebook: Ein vorkonfiguriertes JupyterLab-Notebook führt Schritt für Schritt durch die gesamte RAG-Pipeline.
- Transparentes Retrieval: Es ist genau zu sehen, welche Dokumentationsabschnitte die jeweilige Antwort beeinflusst haben – inklusive Relevanzscore und Quell-URLs.
Erweiterbar: Eigene Wissensbasis einbinden, andere Embedding- oder Generierungsmodelle ausprobieren oder die Hybrid-Search-Gewichtung anpassen.

Komponenten der Demo:
- OpenSearch: Verteilte Such- & Analytics-Engine, die das k-NN-Plugin für HNSW-basierte approximierte Nearest-Neighbor-Suche und BM25-Rescoring in einer einzigen Hybrid-Abfrage nutzt. Speichert ca. 4.200 Dokumentationsabschnitte mit 768-dimensionalen Embeddings.
- OpenSearch Dashboards: Web-UI zur Inspektion indizierter Dokumente, zum Durchsuchen von Vektor-Embeddings und zum Testen von Raw Queries über die Dev-Tools-Konsole.
- Ollama: Lokale LLM-Laufzeitumgebung, die beim Start zwei Modelle lädt – nomic-embed-text:v1.5 (~274 MB) für die Embedding-Generierung und llama3.1:8b (~4,7 GB) für die Antwortgenerierung.
- JupyterLab: Vorkonfigurierter Notebook-Server mit einem vollständigen RAG-Pipeline-Notebook, das per Init-Container heruntergeladen wird – mit Setup, Retrieval, Kontext-Formatierung und gestreamter Generierung.
Demo-Ablauf:
- Installation: Demo auf dem bestehenden Kubernetes-Cluster mit einem einzigen
stackablectl-Befehl deployen – Operatoren und alle Datenprodukte werden automatisch eingerichtet. - Embeddings werden automatisch geladen: Ein Kubernetes-Job lädt vorberechnete Embeddings (~89 MB, ~4.200 Abschnitte) von GitHub herunter und indiziert sie mit k-NN-Vektor-Mappings in OpenSearch.
- JupyterLab öffnen: Port-Forward einrichten und das Notebook unter
localhost:8888aufrufen. Das Notebook prüft die Verbindung, zeigt die Dokumentenzahl und führt Schritt für Schritt durch die Pipeline. - RAG-Abfragen erkunden: Fragen zur Stackable-Dokumentation stellen. Produkterkennung, abgerufene Abschnitte mit Scores und die gestreamte LLM-Antwort – alles direkt im Notebook.
- In Dashboards inspizieren: Den
rag-documents-Index in OpenSearch Dashboards durchsuchen und Vektoren sowie Dokument-Metadaten einsehen.
Ausführliche Anleitungen und Anpassungsoptionen finden sich in der Demo-Dokumentation.
Demo: argo-cd-git-ops
GitOps in Aktion mit ArgoCD
Diese Demo zeigt, wie die Stackable Data Platform mit ArgoCD und GitOps-Prinzipien bereitgestellt und verwaltet werden kann. Durch die Speicherung des gewünschten Cluster-Zustands in Git wird sichergestellt, dass jede Änderung versionskontrolliert, nachvollziehbar und automatisch mit der Kubernetes-Umgebung synchronisiert wird.
Highlights:
- GitOps-Workflow: Stackable-Operatoren und -Produkte werden deklarativ über Git-gemanagte Manifest-Dateien bereitgestellt und aktualisiert.
- Automatische Synchronisation: In Git vorgenommene Änderungen werden von ArgoCD automatisch auf den Cluster angewendet.
- Sealed Secrets: Sensible Zugangsdaten lassen sich sicher in Git verwalten – dank Bitnamis Sealed Secrets.
- Airflow-Integration (Beispiel): Airflow-DAGs und Konfigurationen werden durch Commits im Repository aktualisiert.
- Unterstützung mehrerer Umgebungen: Bereitstellungen lassen sich einfach auf Entwicklungs-, Staging- und Produktionsumgebungen ausweiten.

Komponenten der Demo:
- ArgoCD: Ein deklaratives GitOps-Tool für Continuous Delivery in Kubernetes.
- Airflow: Eine Plattform zum programmgestützten Erstellen, Planen und Überwachen von Workflows, wobei DAGs aus Git synchronisiert werden.
- MinIO: S3-kompatibler Speicher für Airflow-Logs und Daten, der Persistenz und Zugriffssicherheit gewährleistet.
- Stackable-Operatoren: Bereitstellung und Verwaltung von Datenprodukten wie Apache Spark, Trino und Kafka mithilfe der Kubernetes-Operatoren von Stackable.
Inhalt der Demo:
- Installation: Die Demo wird mit einem einzigen Befehl auf dem Kubernetes-Cluster bereitgestellt, wobei ArgoCD und alle erforderlichen Operatoren initialisiert werden.
- Zugriff auf ArgoCD: Über die ArgoCD-Weboberfläche lässt sich die Synchronisation zwischen dem Git-Repository und dem Clusterzustand überwachen.
- Git-Integration: Das Demo-Repository wird geforkt, Änderungen an Manifesten oder DAGs vorgenommen und die automatische Anwendung der Updates durch ArgoCD auf den Cluster beobachtet.
- Interaktion mit Airflow: Über die Airflow-Weboberfläche werden Workflows ausgelöst und überwacht, wobei die Logs in MinIO/S3 gespeichert werden.
Diese Demo bietet einen skalierbaren, nachvollziehbaren und automatisierten Ansatz für die Verwaltung der Datenplattform. Sie dient als Blaupause für die Implementierung von GitOps in Produktionsumgebungen, reduziert manuelle Eingriffe und erhöht die Konsistenz. Ausführliche Anleitungen und Anpassungsmöglichkeiten finden sich in der Dokumentation.
HOW-TO zum Starten,
im Kubernetes-Cluster
Option 1 – explorativ:
stackablectl demo install argo-cd-git-ops --namespace argo-cd
Option 2 – interaktiv:
stackablectl demo install argo-cd-git-ops --namespace argo-cd --parameters customGitUrl=<my-demo-fork-url> --parameters customGitBranch=<my-custom-branch-with-changes>
Demo: jupyterhub-keycloak
Stackable und JupyterHub
Diese Demo zeigt eine umfassende Multi-User Data Science-Umgebung auf Kubernetes, die die Stackable Data Platform mit JupyterHub und Keycloak für eine robuste Benutzerauthentifizierung und Identitätsverwaltung integriert.
Highlights:
- Authentifizierung für JupyterHub: Verwendet Keycloak für die Verwaltung des Benutzerzugriffs und gewährleistet sichere und verwaltbare Authentifizierungsprozesse.
- Dynamische Spark-Integration: Demonstriert die Fähigkeit, einen verteilten Spark-Cluster direkt von einem Jupyter-Notebook aus zu starten, mit dynamischer Ressourcenzuweisung, die auf die Bedürfnisse der Benutzer zugeschnitten ist.
- S3-Speicher-Interaktion: Veranschaulicht das Lesen von und Schreiben auf einen S3-kompatiblen Speicher (MinIO) mit Spark, mit sicherer Verwaltung von Anmeldeinformationen durch Kubernetes-Geheimnisse.
- Skalierbar und flexibel: Nutzt Kubernetes für ein skalierbares Ressourcenmanagement und ermöglicht es Benutzern, je nach Bedarf aus vordefinierten Ressourcenprofilen auszuwählen.
- Benutzerfreundliche GUI: Bietet eine intuitive Umgebung für Data Scientists zum einfachen Umgang mit gängigen Datenoperationen.

Komponenten der Demo:
- JupyterHub: Ein Mehrbenutzer-Server für Jupyter-Notebooks, der die kollaborative Datenanalyse und -verarbeitung ermöglicht.
- Keycloak: Eine Lösung zur Identitäts- und Zugriffsverwaltung, die die Authentifizierung und Autorisierung von Usern übernimmt.
- MinIO: Eine S3-kompatible Speicherlösung zum sicheren Speichern und Abrufen von Daten.
- Apache Spark: Eine einheitliche Analyse-Engine für die Verarbeitung großer Datenmengen, die so konfiguriert ist, dass sie im Client-Modus mit dynamischem Executor-Management läuft.
Inhalt der Demo:
- Installation: Die Demo wird mit einem einfachen Befehl auf einem bestehenden Kubernetes-Cluster installiert, wobei automatisch auch alle erforderlichen Operatoren und Datenprodukte eingerichtet werden.
- Zugriff auf JupyterHub: User navigieren zur JupyterHub-Weboberfläche und melden sich mit vordefinierten Anmeldedaten an, die über Keycloak authentifiziert werden.
- Datenverarbeitung: User können ein Notebook-Profil auswählen und mit der Verarbeitung von Daten mithilfe der bereitgestellten Notebooks beginnen, die verschiedene Datenoperationen gegen S3-Speicher demonstrieren.
- Multi-User-Umgebung: Die Demo unterstützt mehrere gleichzeitige User, alle mit eigenen isolierten Umgebungen für Datenverarbeitungsaufgaben.
Diese Demo bietet eine robuste Vorlage für Data Scientists zur Erstellung komplexer Datenoperationen in einer sicheren und skalierbaren Umgebung.
Weitere Details und Anpassungsoptionen findest Du im Demo-Notebook und in den Konfigurationsdateien. Mehr dazu erfährst Du in der Dokumentation.
Demo: end-to-end-security
Integrierte Datensicherheit
Diese Technologie-Demo zeigt einige der neuesten Stackable-Features mit Fokus auf End-to-End-Sicherheit: Sie demonstriert, wie Single Sign-on plattformübergreifend funktioniert und wie Impersonation die Trennung von Datenzugriffen ermöglicht. Darüber hinaus werden fortgeschrittene Anwendungsfälle wie Row-Level Security und Data Masking für kritische Daten veranschaulicht.
Die Demo basiert auf einem Data-Lakehouse-Auszug aus dem TPC-DS-Schema – einem Decision-Support-Benchmark – und illustriert damit die leistungsstarken Analyse-Fähigkeiten der Plattform.
Technologisch baut die Demo auf Elementen früherer Demos auf:
- HDFS mit Iceberg: Das Hadoop Distributed File System für skalierbare und zuverlässige Speicherung großer Datenmengen – konfiguriert mit Apache Iceberg als Tabellenformat.
- Hive: Eine auf Hadoop aufbauende Data-Warehouse-Infrastruktur für Datenzusammenfassung, Abfragen und Analysen.
- Trino: Eine schnelle, verteilte SQL-Engine für interaktive Analysen mit leistungsstarken Abfragemöglichkeiten über große Datensätze.
- Open Policy Agent (OPA): Eine universelle Policy-Engine für granulare Zugriffskontrolle und einheitliche Policy-Durchsetzung über alle Stackable Data Apps hinweg.
- Superset: Eine moderne Plattform zur Datenexploration und -visualisierung für intuitive Dateneinblicke.
- Spark: Eine einheitliche Analytics-Engine für groß angelegte Datenverarbeitung – eingesetzt für Data Engineering, Data Science und Machine Learning.

Außerdem zeigt die Demo neue Sicherheitskomponenten:
- Kerberos: Ein Netzwerk-Authentifizierungsprotokoll, das entwickelt wurde, um eine starke Authentifizierung für Client-Server-Anwendungen unter Verwendung von Kryptographie mit geheimen Schlüsseln zu ermöglichen, und jetzt auf Kubernetes für eine sichere Authentifizierung läuft.
- Rego-Regeln: Die Policy-Sprache für OPA, die die Erstellung komplexer Policy-Entscheidungen für eine feingranulare Zugriffskontrolle ermöglicht.
- OpenID Connect (OIDC): Eine einfache Identitätsschicht, die auf dem OAuth 2.0-Protokoll aufbaut und es Clients ermöglicht, die Identität von Nutzern zu überprüfen und deren Profilinformationen sicher abzurufen.
- Keycloak: Zusätzlich zur der Stackable Data Platform – eine Open-Source-Lösung für die Identitäts- und Zugriffsverwaltung. Sie verwaltet die Benutzerauthentifizierung und -autorisierung und bietet Single Sign-On (SSO) für verschiedene Anwendungen.
Das Ergebnis ist ein für die fiktive „knab“-Organisation erstelltes leistungsstarkes und sicheres Template für einen modernen Data Stack mit der Stackable Data Platform.
Demo: data-lakehouse-iceberg-trino-spark
Data Lakehouse Technologie Showcase
Diese Technologie-Demo zeigt einige der Funktionen der neuesten Features von Stackable.
Die Demo enthält Elemente früherer Demos, z.B.
- Echtzeit-Event-Streaming mit Apache NiFi
- Trino für SQL-Zugriff und
- visuelle Datenanzeige und -analyse mit Apache Superset
Zusätzlich enthält die Demo aber auch neue Lakehouse-Funktionen wie die Integration mit Apache Iceberg, die z. B. transaktionale Konsistenz und vollständige Schema-Evolution bietet.
Das Ergebnis ist eine umfassende Vorlage für einen modernen Data Stack mit der Stackable Data Platform.
Weitere Highlights der Demo:
- Apache Spark: Eine mehrsprachige Engine für die Ausführung von Data Engineering, Data Science und maschinellem Lernen. In dieser Demo wird es verwendet, um Daten von Kafka in das Lakehouse zu streamen.
- Open Policy Agent (OPA): Eine quelloffene, universell einsetzbare Policy-Engine, die die Durchsetzung von Richtlinien im gesamten Stack vereinheitlicht. In dieser Demo wird sie als Autorisierer für Trino verwendet, um zu entscheiden, welcher Benutzer welche Daten abfragen darf.
HOW-TO zum Starten,
im Kubernetes-Cluster:
stackablectl demo install data-lakehouse-iceberg-trino-spark
(Hinweis: getestet mit 10x4Core Nodes jeweils mit 20GB RAM ind 30GB HDD, Persistent Volumes mit Gesamtgröße ca. 1TB)
Anmerkung: für ein kleineres Setup, schau Dir gern unsere trino-iceberg Demo an:
stackablectl demo install trino-iceberg
Demo: SPARK-K8S-ANOMALY-DETECTION-TAXI-DATA
Machine Learning zur Ausreißererkennung
Diese Stackable-Data-Platform-Demo stellt eine Erweiterung der ursprünglichenTRINO-TAXI-DATA-Demo um Apache Spark™ dar.

Ein oft vernachlässigter Faktor beim Einsatz von Daten zum Machine Learning ist die Datenqualität. Falschmessungen, fehlende Werte und ähnliches verfälschen die spätere Prognosequalität. In bestimmten Szenarien sind Spitzen, Ausreißer oder andere Anomalien in den Daten auch relevant, in dem sie eine Grundlage für die Definition von Warnmeldungen bilden können.
Somit liefert die Erkennung von Ausreißern einen wichtigen Beitrag für die erfolgreiche Nutzung von Daten. Wissenschaft und Wirtschaft setzen in der Praxis hier heutzutage eine Vielzahl an Verfahren und Methoden ein.
In dieser Demo erfolgt die Ausreißererkennung exemplarisch mit Apache Spark, indem ein Isolation Forest Algorithmus auf die Daten ausgeführt wird. Der Isolation-Forest-Algorithmus wird für das unüberwachte Modelltraining (unsupervised model training) verwendet, was bedeutet, dass das Modell ohne Labelling auskommt.
Ergebnisse der Erkennung werden im Apache Iceberg Format gespeichert und mit Apache Superset visualisiert.
HOW-TO zum Starten,
im Kubernetes-Cluster:
stackablectl demo install spark-k8s-anomaly-detection-taxi-data
Demo: NIFI-kafka-druid-water-level-data
Echtzeitanzeige von Wasserpegelständen
Niedrigwasser oder Überschwemmungsgefahr – die Wasserpegel unserer Flüsse sind in Zeiten des Klimawandels ins öffentliche Interesse gerückt.
Unsere Stackable-Data-Platform-Demo zeigt die Pegelstände von Flüssen nahezu in Echtzeit auf Basis der Daten von Pegel Online.

Mehrere Komponenten der Stackable Data Platform spielen dabei zusammen, ohne dass dafür ein großer Konfigurationsaufwand notwendig ist:
Mit Apache Nifi und Apache Kafka werden Pegelstandsmessungen von deutschlandweit verteilten Messstationen über eine API von Pegel Online abgeholt und in Apache Druid gespeichert.
Druid ist eine skalierbare Echtzeitdatenbank, die mittels SQL abgefragt werden kann. Diese Methode wird in der Demo genutzt, um über Apache Superset die Pegelstände abzufragen und im Dashboard zu visualisieren. Für die dauerhafte Speicherung benötigt Druid einen sogenannten „Deep Storage“, der in unserem Beispiel über MinIO als S3-kompatibler Objektspeicher, wie er in den meisten öffentlichen und privaten Cloud-Umgebungen vorhanden ist, realisiert wird.
HOW-TO zum Starten,
im Kubernetes-Cluster:
stackablectl demo install nifi-kafka-druid-water-level-data
Demo: NIFI-kafka-druid-earthquake-data
Event Streaming von Erdbeben-Daten
Diese Stackable-Data-Platform-Demo zeigt gestreamte Erdbebendaten bis zur Anzeige im Dashboard.
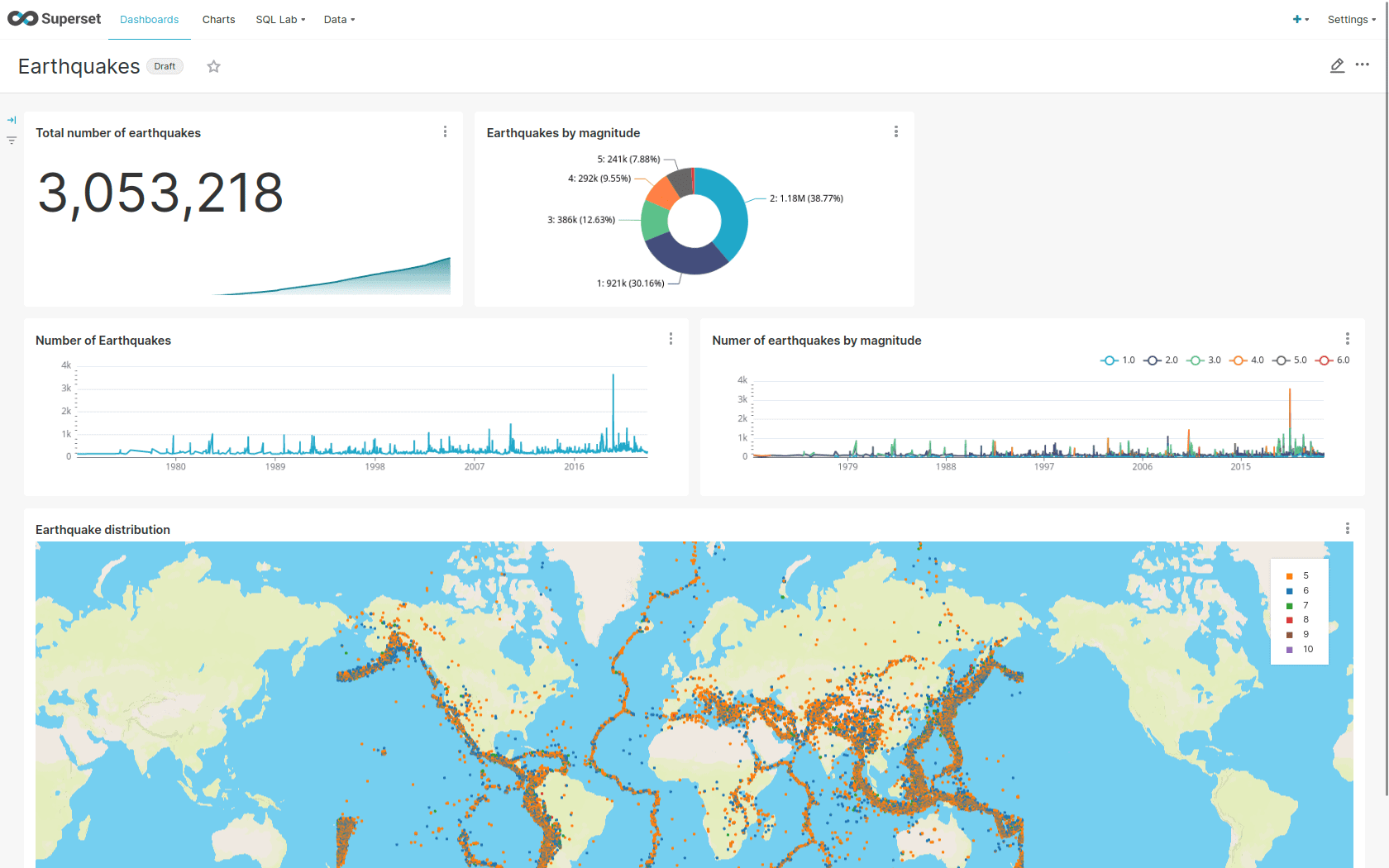
Sie enthält folgende Operatoren:
-
Apache Superset: Eine moderne Plattform zur Datenexploration und -visualisierung. Diese Demo nutzt Superset, um Daten von Druid über SQL-Abfragen abzurufen und Dashboards auf diesen Daten aufzubauen.
-
Apache Kafka®: Eine verteilte Event-Streaming-Plattform für leistungsstarke Datenpipelines, Streaming-Analysen und Datenintegration. In dieser Demo wird Kafka als Event-Streaming-Plattform verwendet, um die Daten nahezu in Echtzeit zu streamen.
-
Apache Nifi: Ein einfach zu bedienendes, leistungsstarkes System zur Verarbeitung und Verteilung von Daten. Diese Demo verwendet es, um Erdbebendaten aus dem Internet zu holen und in Kafka zu übertragen.
-
Apache Druid: Eine Echtzeit-Datenbank zur Unterstützung moderner Analyseanwendungen. Diese Demo verwendet Druid, um Daten nahezu in Echtzeit aus Kafka aufzunehmen, zu speichern und den Zugriff auf die Daten über SQL zu ermöglichen.
-
MinIO: Ein S3-kompatibler Objektspeicher. In dieser Demo wird er als persistenter Speicher für Druid verwendet, um alle gestreamten Daten zu speichern.
HOW-TO zum Starten,
im Kubernetes-Cluster:
stackablectl demo install nifi-kafka-druid-earthquake-data
Demo: trino-taxi-data
Analysen mit einem Data Lake
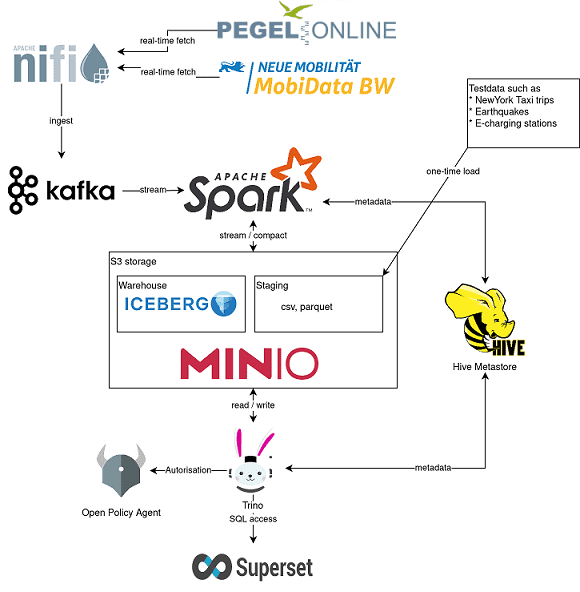
Diese Stackable-Data-Platform-Demo zeigt in S3 gespeicherte Daten für die Analyse und bis zur Anzeige im Dashboard.

Mit unseren Stackable-Operatoren werden verschiedene Komponenten konfiguriert und ausgerollt. Dieses Beispiel zeigt insbesondere, wie ein rollenbasierter Datenzugriff über den Open Policy Agent realisiert werden kann:
- In MinIO, einem S3-kompatiblen Objektspeicher, werden die Daten für diese Demo persistent gespeichert.
- Hive-Metastore speichert die notwendigen Metadaten, um die Beispieldaten über SQL zugreifbar zu machen und wird in unserem Beispiel von Trino verwendet.
- Trino ist unsere extrem schnelle, verteilte SQL-Abfrage-Engine für Big-Data-Analysen, mit der sich Datenräume erkunden lassen und die wir in der Demo verwenden, um SQL-Zugriffe auf die Daten zu ermöglichen.
- Apache Superset verwenden wir schließlich, um Daten von Trino über SQL-Abfragen abzurufen und Dashboards auf diesen Daten aufzubauen.
Open Policy Agent (OPA): Eine quelloffene, universelle Policy Engine, die die Durchsetzung von Richtlinien im gesamten Stack vereinheitlicht. In dieser Demo autorisiert OPA, welcher Benutzer welche Daten abfragen darf.
Du hast Fragen oder Anmerkungen?
Mehr Infos?
Kontaktiere Sönke Liebau, um mit uns in Kontakt zu treten:

Sönke Liebau
CPO & CO-FOUNDER von Stackable
Subscribe to our Newsletter
With the Stackable newsletter, you’ll always stay up to date on the latest from Stackable!

Newsletter
Subscribe to the newsletter
With the Stackable newsletter you’ll always be up to date when it comes to updates around Stackable!