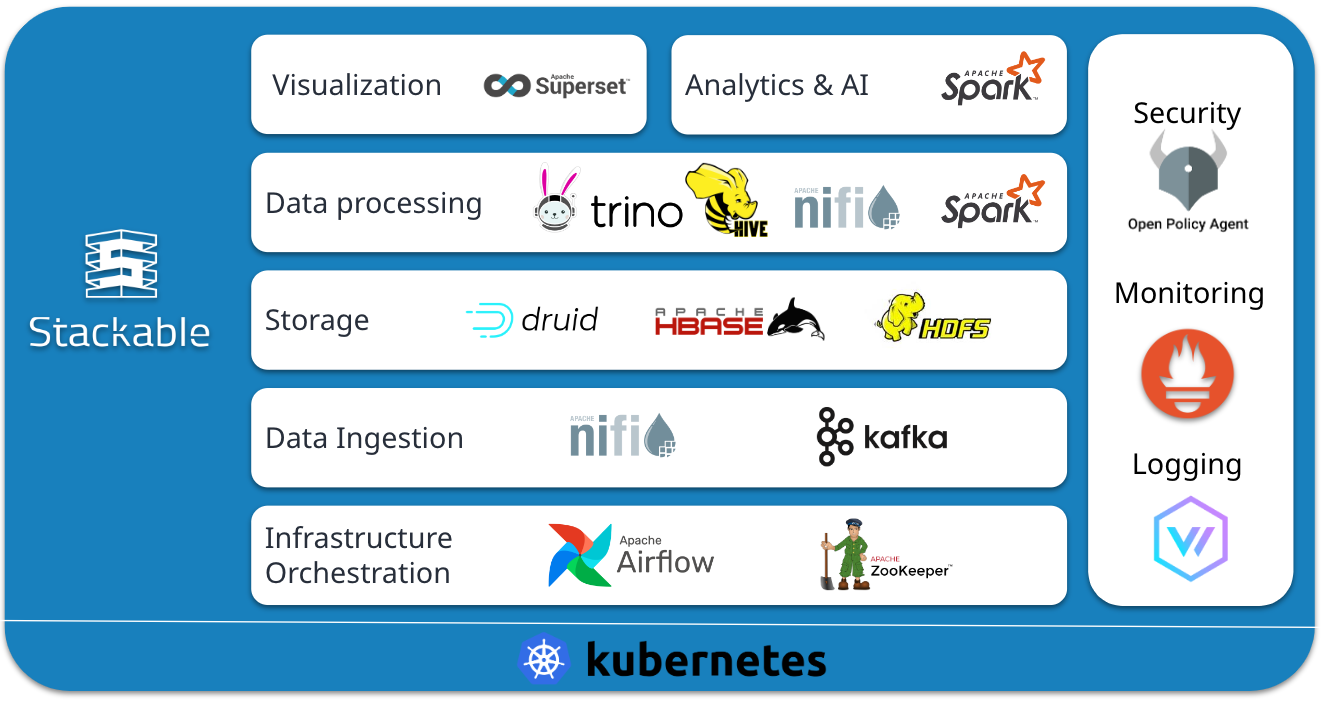
Open Source Datenplattform


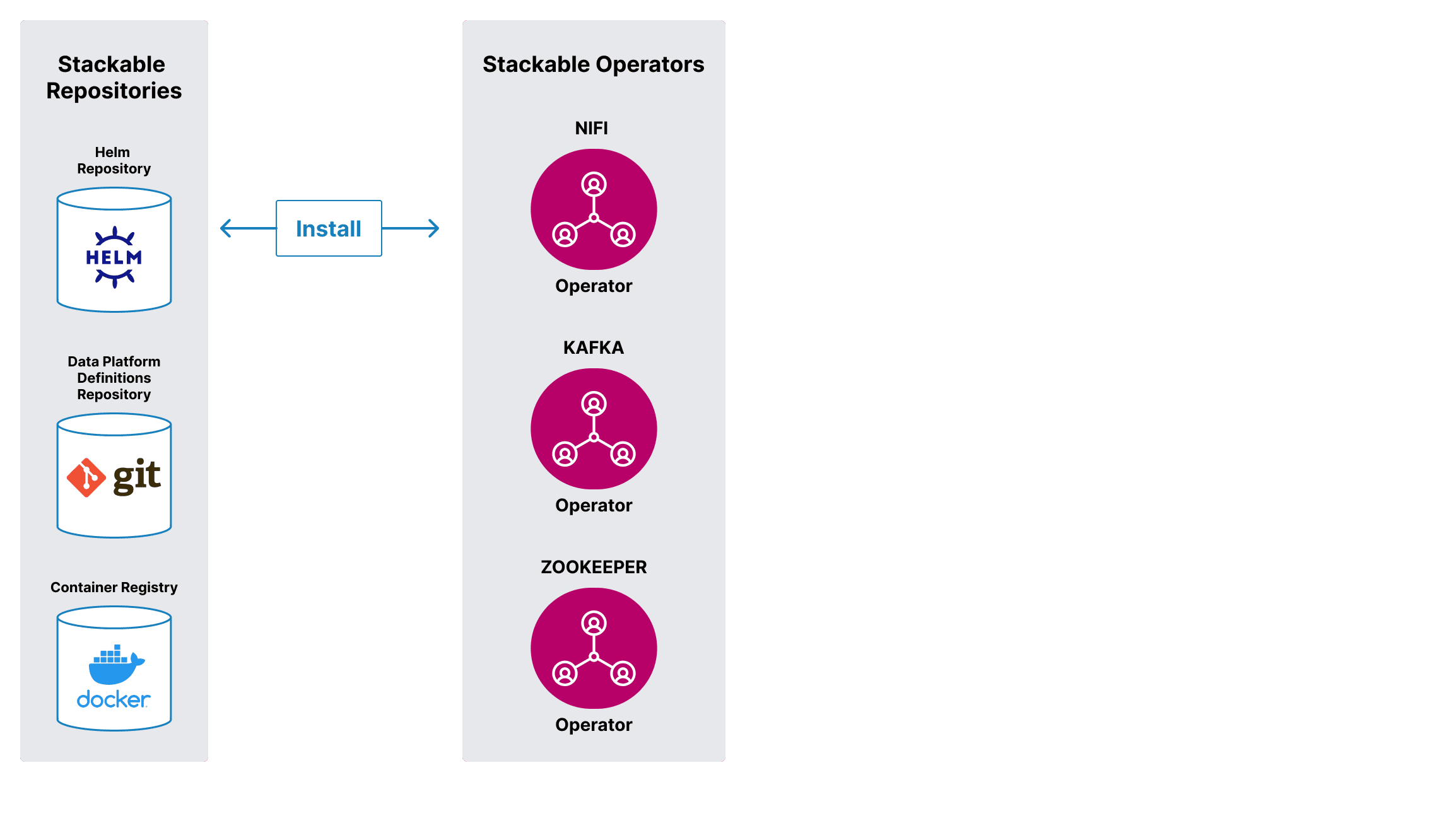
1. Operatoren und...
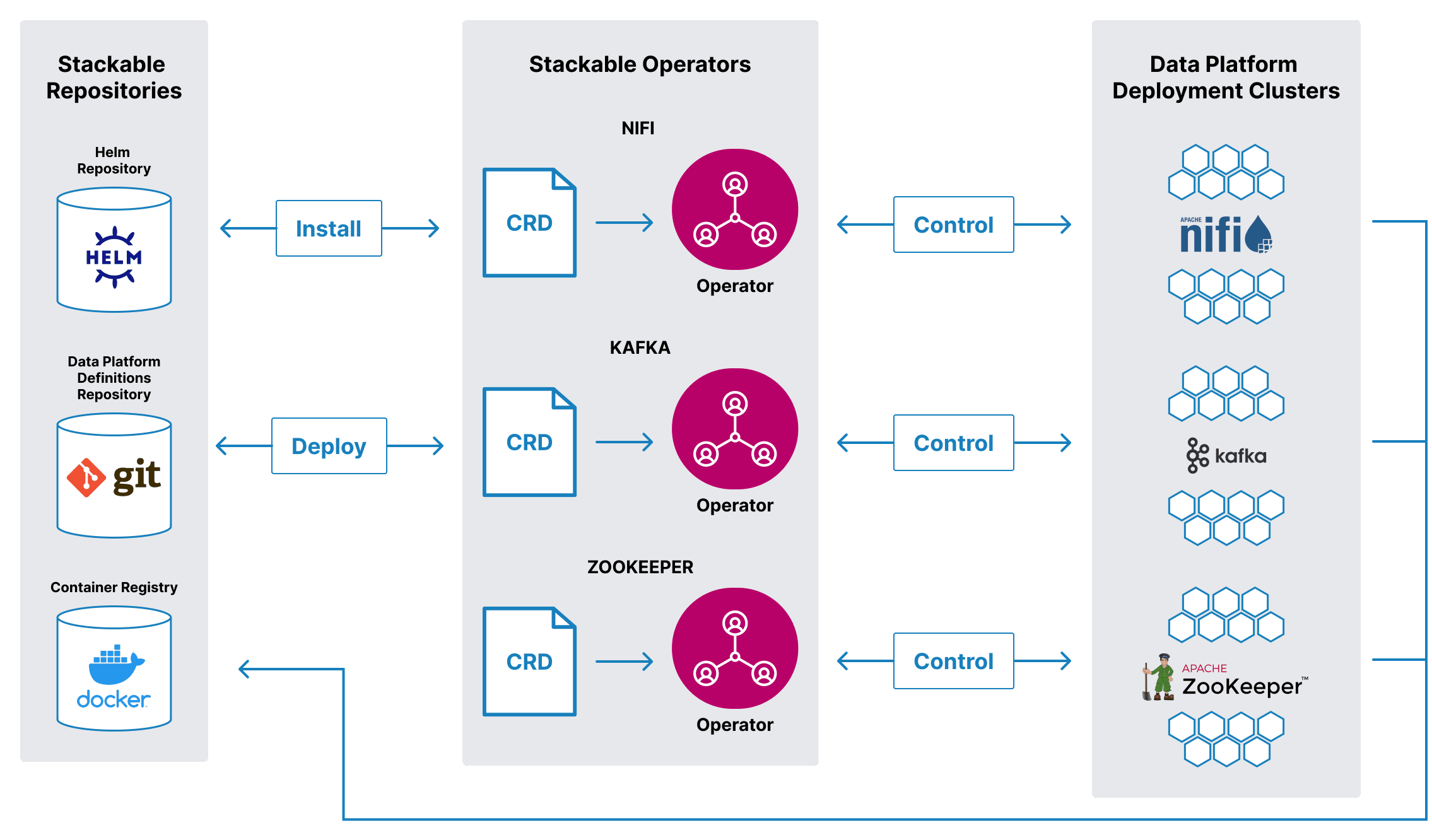
2. ... Konfigurationen
1. Operatoren und...
2. ... Konfigurationen


Open Source Datenplattform