


The Stackable Data Platform is a distribution for Big Data software running on-premise or in the cloud. Open-source, written in Rust and designed for use in Kubernetes environments, Stackable operators are available for many popular Big Data components and allow users to define their data infrastructure as code. The spark-k8s-operator has been developed as part of the Marispace-X project. Marispace-X is a project funded by the Federal Ministry for Economic Affairs and Climate Protection in the context of Gaia-X. The aim is to build a maritime data ecosystem that allows stakeholders from business, science, public authorities and NGOs to securely manage, distribute and analyze the data obtained from the sea.
The Operator is specifically tailored to the needs of Data Scientists. It leverages the strengths of the Kubernetes runtime environment: dynamic resource allocation, flexible job dependency management, and built-in security.
However, for Spark users familiar with Yarn-managed clusters, there are also some important differences in running Spark jobs according to the “Kubernetes paradigm”. This article will introduce the Stackable Spark-on-Kubernetes operator, illustrate how it is different from our other operators, and explain several use cases. For more detailed information, please consult the current operator documentation here: https://docs.stackable.tech/home/nightly/spark-k8s/
Spark-on-YARN
The initial release of Spark in 2012 marked a significant change in the approach to coding Map-Reduce jobs (whereby the code is distributed to where the data is stored, rather than vice–versa). Prior to that release it was common to write these jobs either directly in Java, the Pig script language (pipeline-based) or Hive (sql-based). The advent of Spark changed some of that: HDFS was no longer required, as Spark could interact directly with different file formats, and the execution speed was significantly superior. Challenges remained, though, as job dependencies and scheduling conflicts created their own pain points.
Spark-on-Kubernetes
The early-2021 release of Spark 3.1.1 included the ability to run jobs over a Kubernetes Cluster Manager (see the release announcement https://spark.apache.org/releases/spark-release-3-1-1.html and related issue here https://issues.apache.org/jira/browse/SPARK-33005 for more information). It was already possible to run against a standalone cluster running in Kubernetes, but support for the Kubernetes paradigm added significant flexibility. The main differences are summarized below:
Standalone
- Spark-submit addresses an endpoint of the form spark://
- Spark jobs are executed by a static cluster i.e. a fixed number of executors
- Jobs are executed in a first-in-first-out manner
- Resource-based scheduling and job prioritization is challenging (e.g. there is no fair-scheduler)
Kubernetes
- Spark-submit addresses an endpoint of the form k8s://
- Spark jobs are managed by the driver, which spins up pods based on the resource definitions
- Jobs can take advantage of node affinity and run independently of each other (although the true degree of parallelism is determined by the underlying resources)
For the sake of completion we should mention that spark jobs defined within kubernetes can also be executed against an external hadoop cluster, where the spark-submit job addresses the maybe more familiar yarn:// endpoint. Perhaps the clearest advantage of this approach is the fact that we are staying faithful to the true map-reduce paradigm of sending our algorithm to the data rather than vice-versa. The kubernetes paradigm is fundamentally different: it is more of an “extract-map-reduce” approach, as the data is first made available to the executor pods – introducing network traffic as a potential bottleneck (extract) – which then run in parallel (map) before consolidating the partial results (reduce).
Overview
The advantages that Kubernetes offers for spark users clearly make it an attractive proposition: integrated security, cluster supervision/self-healing and dynamic resource allocation mean that more attention can be given to the job itself. So how does it work? A bird’s-eye view is given below:
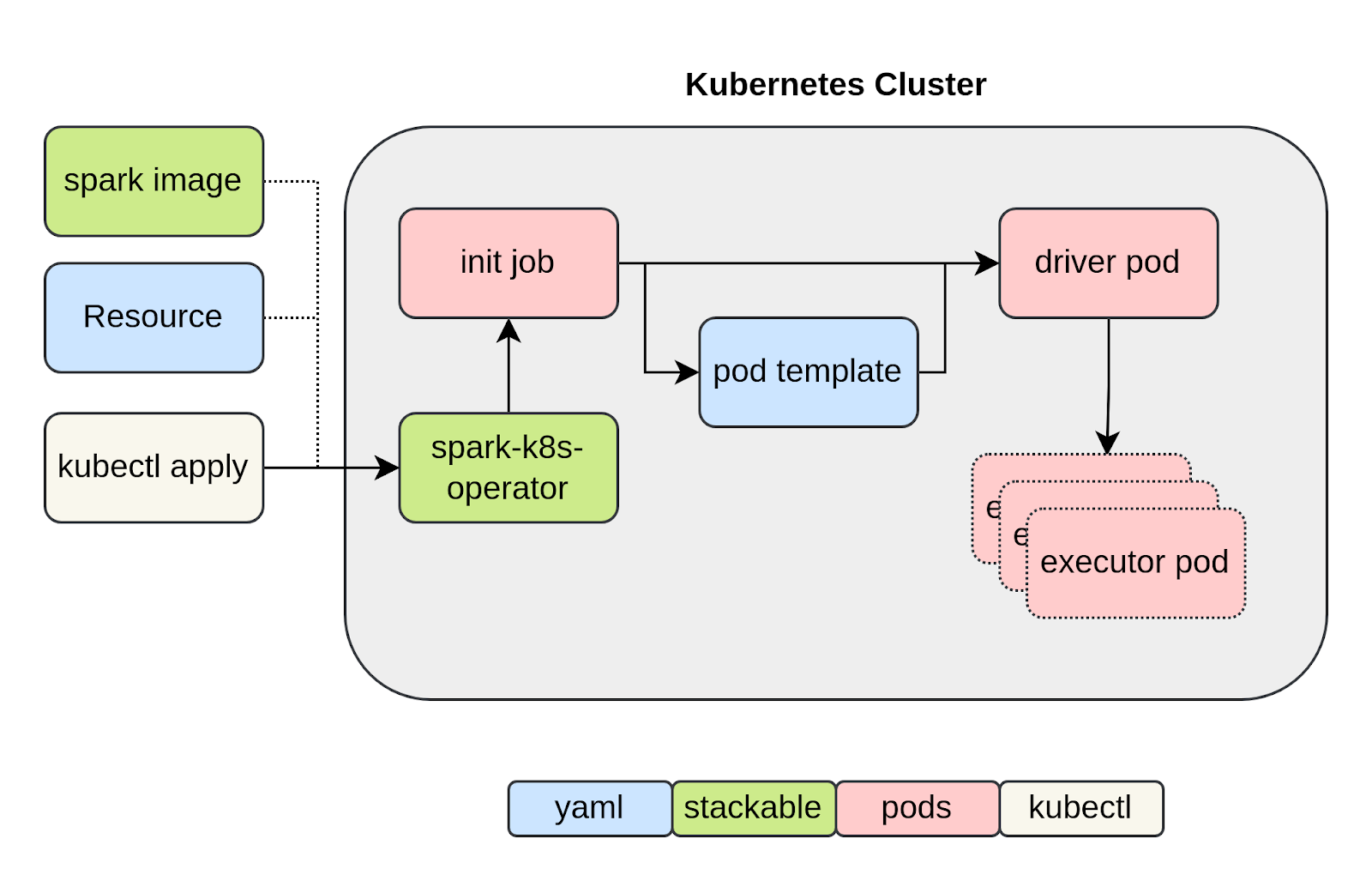
There are two main steps in this process:
- The user defines a SparkApplication Resource which is parsed by the operator into a spark-submit command which is then executed by a pod created by the operator
- This job pod spawns a driver pod, which in turn spawns the declared number of executors
For this to be possible – i.e. for the driver to know how to configure the executor pods – you need to define a pod template and make it available to the pod responsible for creating the driver. This template is also passed by the driver to each executor pod. Additionally, although Spark can access job dependencies held in an external location such as an S3 object-store bucket, it needs certain dependencies to be able to access this location in the first place. There is now a chicken-and-egg problem: if Spark is to fetch dependencies from S3, it needs other dependencies to do so (typically AWS libraries to talk to S3 endpoints). This means that you have to make a distinction between dependencies that can be accessed at job execution time, and those that must be made available beforehand, either by baking them into the image or by mounting them before the driver is created. Other dependencies can either be passed via spark configuration options or – in the case of python libraries – installed in the pod directly.
The main take-away from all this is that you do not have any “direct” access to an executor pod. This makes the creation process a little convoluted, but has the advantage of not needing a mutation webhook to actively change a pod once it is created. This is one of the differences between the Stackable spark-k8s-operator and the one developed by Google (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator).
Dependency management
This is described in detail here https://docs.stackable.tech/home/nightly/spark-k8s/usage-guide/job-dependencies but we can summarize the possibilities as follows:
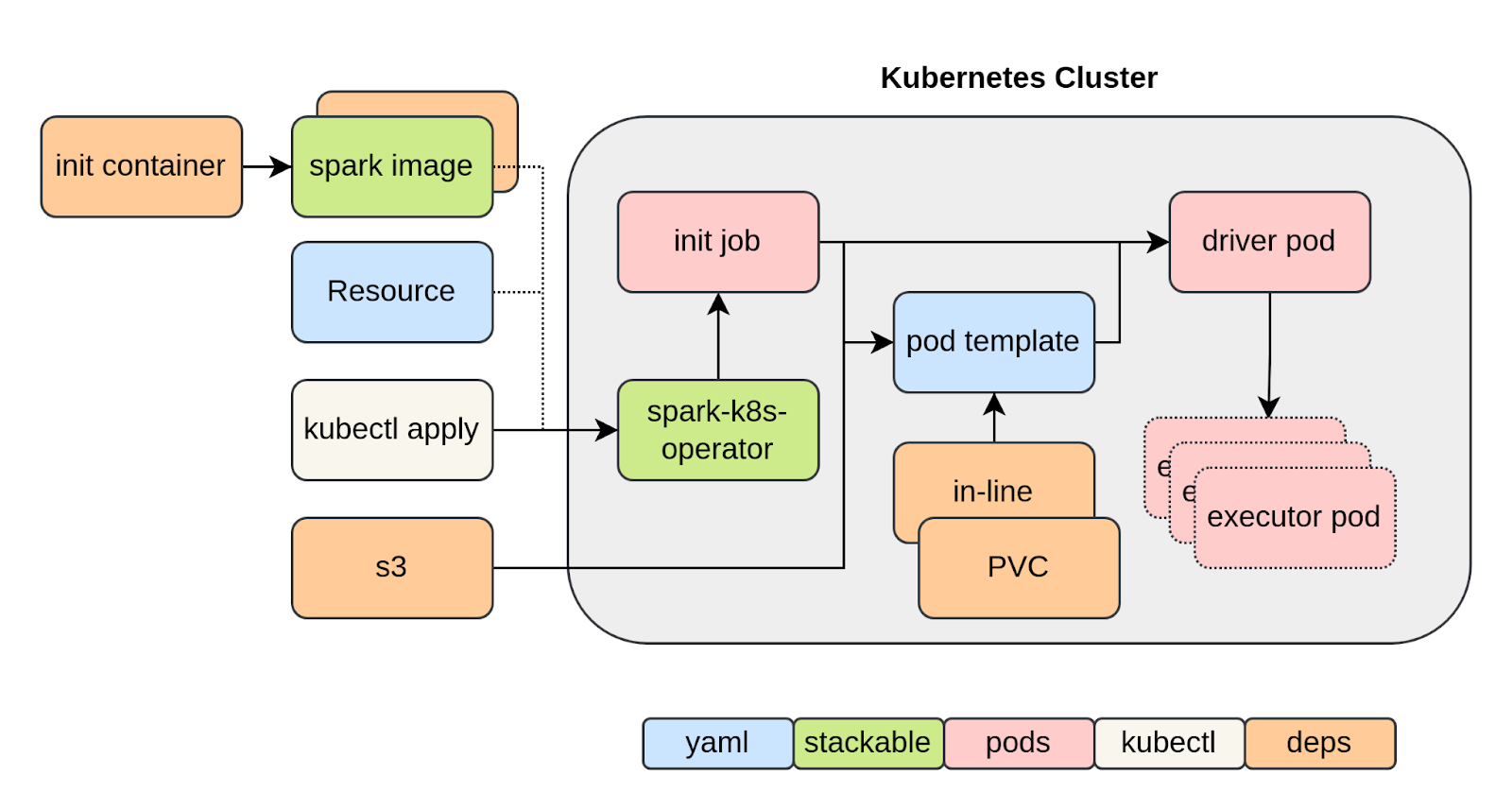
- You can bake everything into the image used for all stages of the job (i.e. for the initiating job, the driver and all executor pods, as the same image will be used consistently). This approach is transparent – you have everything in one place and you can inspect the image before using it – but means that the image can be fairly large.
- Packages can be installed “in-line” in the driver and executor pods, either by listing them for explicit execution by pip (python packages), or by defining the maven coordinates from where packages can be downloaded from the specified repositories and passed as spark-submit arguments for spark to process itself.
- Dependencies can be retrieved from an external location such as an S3 object store
- Dependencies can be provisioned from a PersistentVolume in the Kubernetes cluster. An example of this is shown below.
Let’s look at a specific example that illustrates the use of a dependency volume (taken from documentation here https://docs.stackable.tech/home/nightly/spark-k8s/usage-guide/job-dependencies#_dependency_volumes).
First you define a PersistentVolume:
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-ksv (1)
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
capacity:
storage: 2Gi
hostPath:
path: /some-host-location
Kubernetes supports several different storage types that back a PersistentVolume. In this case you are mounting a location from the host system, but it could also be any of the plugins supported by Kubernetes (see https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes).
You give this PersistentVolume a name (1) which you will reference in the PersistentVolumeClaim, shown next:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-ksv (2)
spec:
volumeName: pv-ksv (1)
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
The PersistentVolumeClaim is referenced by its name (2) in the initialization job: the Job uses the PVC to back a volume (3) and executes a set of commands (4) to populate this volume that is mounted at the location specified (5).
---
apiVersion: batch/v1
kind: Job
metadata:
name: aws-deps
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: job-deps (3)
persistentVolumeClaim:
claimName: pvc-ksv (2)
command:
[
…(populate the mount path at e.g. /dependencies/jars)… (4)
]
containers:
- name: aws-deps
volumeMounts:
- name: job-deps (5)
mountPath: /dependencies
Let’s recap what you have done: you have started a job that will execute a series of actions (curl, git, wget etc.) to populate a location local to it (/dependencies) which is also the mountPath of a volume backed by a PersistentVolumeClaim. This means that whatever process has access to the same PersistentVolumeClaim will be able to read those same resources at the same location. So when you define a SparkApplication custom resource like the one below, you can do just that: by defining a volume backed by the PersistentVolumeClaim you thereby have access to these same resources at the path you have defined above i.e. /dependencies.
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: example-sparkapp-pvc
namespace: default
spec:
version: "1.0"
sparkImage: docker.stackable.tech/stackable/spark-k8s:3.2.1-hadoop3.2-stackable0.4.0
mode: cluster
mainApplicationFile: s3a://stackable-spark-k8s-jars/jobs/ny-tlc-report-1.0-SNAPSHOT.jar (1)
mainClass: org.example.App (2)
args:
- "'s3a://nyc-tlc/trip data/yellow_tripdata_2021-07.csv'"
sparkConf: (3)
"spark.hadoop.fs.s3a.aws.credentials.provider": "org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider"
"spark.driver.extraClassPath": "/dependencies/jars/hadoop-aws-3.2.0.jar:/dependencies/jars/aws-java-sdk-bundle-1.11.375.jar"
"spark.executor.extraClassPath": "/dependencies/jars/hadoop-aws-3.2.0.jar:/dependencies/jars/aws-java-sdk-bundle-1.11.375.jar"
volumes:
- name: job-deps (4)
persistentVolumeClaim:
claimName: pvc-ksv
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
volumeMounts:
- name: job-deps
mountPath: /dependencies (5)
executor:
cores: 1
instances: 3
memory: "512m"
volumeMounts:
- name: job-deps
mountPath: /dependencies (5)
There are a few more things going on here, so let’s just run through some of the things that are annotated:
(1): this is the job artifact, in this case provisioned directly from an external S3 bucket
(2): for JVM-based jobs (Java, Scala) you need to tell Spark which class is the entrypoint, which you do here
(3): these elements will be passed directly to the spark-submit command as arguments. The jar files that the you prepared in the job can be made available to spark by declaring that they are found in a secondary class path and the job artifact that you retrieve from the S3 bucket is publicly available and so it suffices to tell Spark that you need no credentials by specifying AnonymousAWSCredentialsProvider.
(4) & (5): this is a similar pattern to one you had in the job above: you are telling the Custom Resource to mount your volume backed by the PersistentVolumeClaim/PersistentVolume at /dependencies, from where you have retrieved your jar files.
Image policies
The nature of Spark jobs and the management of their dependencies is such that users will often want to use their own images – and these will probably be stored in private repositories. To make it easier to do this you can define both the pull policy for the images and secrets that are to be used when accessing private repositories. These (along with all other settings) are described here: https://crds.stackable.tech/spark-k8s-operator/nightly/.
Future Work
Spark-k8s-operator 0.5.0 is the current release at the time of writing. A few of the issues in the backlog for future releases are outlined below.
Benchmarking / Hardware acceleration
Map/Reduce jobs executed by Spark in a Kubernetes cluster differ slightly from the classical M/R paradigm in that you have to get all dependencies into Kubernetes before they are parceled out to the individual executor pods. Spark is not running on, say, hdfs, where each node also is an hdfs node. One can think of it more as an “Extract-Map-Reduce” paradigm, where the overhead of the “Extract” step is not nearly as significant as it would have been several years ago, due to improvements in band-width and network latency etc. Nevertheless, adding in layers of abstraction brings with it potential hidden bottle-necks and so you are planning to look at various ways of using hardware acceleration to optimize job behavior.
Logging
Getting a consolidated view of spark job logs distributed across all tasks was difficult enough in the old days of YARN, but with the Spark-on-Kubernetes there is the additional challenge that the executors are cleaned up as soon as the job has completed. A reliable logging solution should be able to capture and consolidate these logs.
Node Affinity
Spark supports node selection, whereby it is possible to direct jobs to a specific set of nodes (see https://spark.apache.org/docs/latest/running-on-kubernetes.html#how-it-works). The spark-k8s-operator implements this currently, and the aim is to add node/pod affinity support in the future.
Wrap-up
The spark-k8s-operator is in its first release yet has already benefited from valuable input from our partners in the Marispace-X project. Over the course of the summer we will be adding further improvements – stay tuned!