


TL;DR
Apache Spark™ is a powerful engine for big data analytics — but traditionally, connecting tools and applications to Spark meant heavyweight dependencies, tight version coupling, and operational complexity.
However, in 2023, the project introduced Spark Connect in Spark 3.4, and with our latest Stackable Data Platform 25.7 release, we have added support for it: a modern, client–server architecture that makes Spark easier to use for data engineers and simpler to maintain for DevOps teams.
Designed to be modular, open and cloud-native, Spark Connect integrates seamlessly with any Stackable-powered data platform.
Spark Connect Architecture
The architecture is similar to client-server communication in relational database management systems, where the server is doing the heavy lifting: A SQL query is sent to the database server as plain text, and the server creates the query plan. It then executes the statement and streams the results back to the client.
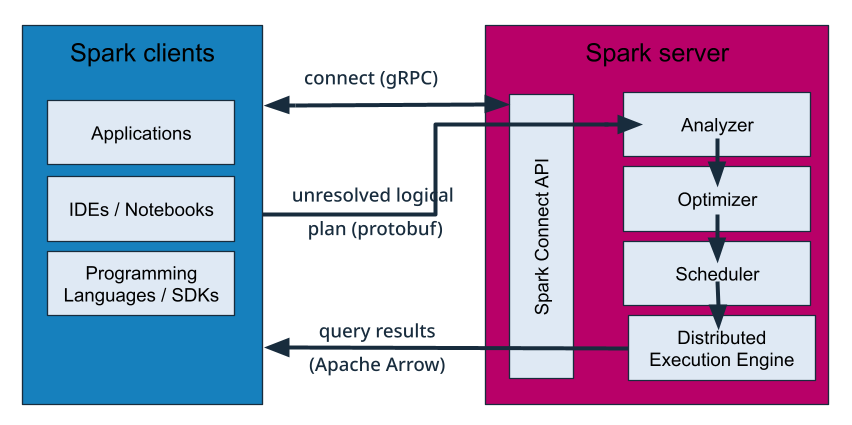
Similarly, Spark Connect decouples client applications from the Spark driver. Rather than embedding the entire Spark runtime locally, client tools generate a logical query plan and transmit it to the cluster via a lightweight gRPC protocol. The Spark cluster then handles optimisation, scheduling and execution, while data transfers use the efficient Apache Arrow columnar format.
This separation enhances scalability, security, and maintainability through client isolation and server-side resource control.
Spark Connect for Data Engineers: lightweight and flexible
Spark Connect offers multi-language support and improved integration with modern tools.
You can build Spark Connect Clients that do not depend on Java/Scala in non-JVM languages like Python (Spark Connect Python), Go( Spark Connect Go), dotnet (Spark Connect dotnet) and even Rust (Spark Connect Rust). Data Engineers, Data Scientists and Software developers can use their own favourite IDE or Jupyter notebooks without having to install any additional software locally.
Spark Connect for DevOps teams: decoupled and maintainable
When you do not use Spark Connect, the client and Spark Driver must run identical software versions.
They require the same versions of Java, Scala and other dependencies. However, as Spark Connect decouples the client and the Spark Driver, you can update the Spark Driver including server-side dependencies without updating the client. This makes Spark projects much easier to maintain.
Spark Connect supports deployment on Kubernetes, YARN, or standalone Spark clusters.
Deploying Spark Connect clusters on Kubernetes gets even easier, more secure and accessible with the Stackable Data Platform and our latest Spark operator version:
Once deployed, the operator monitors the cluster for Spark Connect resources and automatically provisions the necessary workloads and storage connections, as well as publishes access services.
Getting started
The Anomaly Detection Demo available in the Stackable documentation shows how a completely encapsulated environment, using Jupyter Notebooks as clients, can be deployed with minimal effort. The demo also showcases the integration between notebooks, Spark and HDFS to read and aggregate data, train a statistical model and make predictions.
Summary
Spark Connect makes Spark easier to use, run and maintain, thereby strengthening its position as a robust, multi-tenant and language-agnostic analytics service. Spark remains a powerful tool for scalable data processing and machine learning.
Learn more about Spark connect here:
https://spark.apache.org/spark-connect/
https://spark.apache.org/docs/latest/spark-connect-overview.html