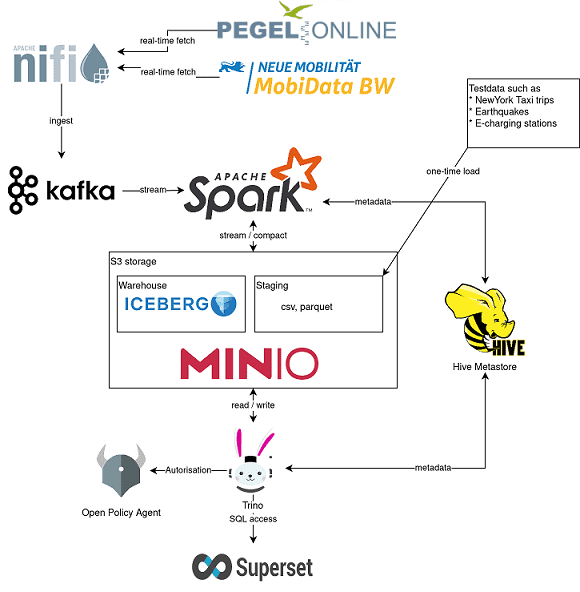
Ermöglicht den Import, das Management des Datenflusses sowie den automatisierten Datenaustausch zwischen Systemen.
- Einfaches Daten-Routing und Transformation: Bietet eine benutzerfreundliche Oberfläche für das Management des Datenflusses und unterstützt die schnelle Entwicklung und Bereitstellung von Verarbeitungspipelines.
- Systemintegration: Verbindet sich mit einer Vielzahl von Datenquellen und -senken und erleichtert die Datenaufnahme aus unterschiedlichen Systemen.
- Data Lineage: Nachverfolgung des Datenflusses von der Quelle bis zum Ziel, Unterstützung von Audits und Compliance.
- Flexibel: Anpassbare Prozessoren und die Fähigkeit, verschiedene Datenformate und -größen zu verarbeiten.
Optimierung von Daten-Workflows mit Präzision und Skalierbarkeit.
- Erweiterte Workflow-Orchestrierung: Apache Airflow bietet die umfassende Planung und Verwaltung von Workflows, die eine präzise Steuerung von Datenverarbeitungsaufgaben innerhalb der Stackable Data Platform ermöglicht.
- Dynamische Erstellung von Pipelines: Mit Hilfe der intuitiven Benutzeroberfläche und des leistungsstarken Programmier-Frameworks von Airflow lassen sich komplexe Datenpipelines einfach definieren, planen und überwachen.
- Skalierbar und verlässlich: Airflow lässt sich einfach skalieren. Gleichzeitige Workflows lassen sich mühelos handhaben, so dass Datenaufgaben unabhängig vom Volumen zuverlässig ausgeführt werden.
- Effizientes Monitoring und Protokollierung: Die Monitoringfunktionen von Airflow ermöglichen eine schnelle Identifizierung und Lösung von Problemen und gewährleisten einen reibungslosen Datenbetrieb.
Bietet leistungsstarke Datenverarbeitungsfunktionen, die verteilte Analysen und maschinelles Lernen auf großen Datensätzen ermöglichen.
- In-Memory-Computing: Beschleunigt die Verarbeitungsgeschwindigkeit, indem es die Daten im RAM speichert, deutlich schneller als festplattenbasierte Alternativen.
- Erweiterte Analysen: Unterstützt komplexe Algorithmen für maschinelles Lernen, Graphenverarbeitung und mehr.
- Fehlertoleranz: Resiliente verteilte Datensätze (RDDs) bieten Fehlertoleranz durch Herkunftsinformationen.
- Sprachunterstützung: Bietet APIs in Python, Java, Scala und R und erweitert damit die Zugänglichkeit und Nutzbarkeit.
Ermöglicht den (virtualisierten) Datenzugriff über verschiedene Datenquellen hinweg und verbessert die Flexibilität und Geschwindigkeit von Abfragen in Datenarchitekturen.
- Flexible Tabellenformate: Unterstützung von Apache Iceberg und Delta Lake.
- Schnelle Antwortzeiten: Entwickelt für performante Datenabfragen über verteilte Datenquellen hinweg.
- Föderierte Abfragen: Ermöglicht die Abfrage von Daten aus mehreren Quellen und vereinfacht die Analyse über unterschiedliche Datenspeicher (Data Federation).
- Skalierbar und flexibel: Einfache Skalierung für große Datensätze und komplexe Abfragen.
- Benutzerfreundlich: Unterstützt SQL für Abfragen und ist damit auch für Benutzer geeignet, die mit relationalen Datenbanken vertraut sind.
Stackable unterstreicht sein Engagement für offene und flexible Datenlösungen durch die Integration von zwei erstklassigen Tabellenformaten: Apache Iceberg und Delta Lake. Unsere Kunden können somit die beste Option für ihre spezifischen Anforderungen auswählen. Im Folgenden erläutern wir die wichtigsten Faktoren, die bei der Wahl zwischen Delta Lake und Apache Iceberg zu berücksichtigen sind. Wir empfehlen jedoch immer die Durchführung von Tests mit realen Anwendungsfällen, um eine möglichst genaue Entscheidung treffen zu können.
Apache Iceberg:
- Optimal, wenn besonderer Wert auf Benutzerfreundlichkeit und plattformübergreifende Kompatibilität gelegt wird.
- Unterstützt die kontinuierliche Schemaevolution und die Analyse großer Datenzeiträume.
- Aufgrund seiner effizienten Abfrageperformance besonders geeignet für Data Warehousing-Anforderungen.
Delta Lake:
- Perfekt abgestimmt auf Benutzer, die bereits Delta Lake-Architekturen verwenden.
- Hervorragend geeignet für Setups, die ACID-Transaktionen und hohe Datenintegrität erfordern.
- Optimal in Umgebungen, in denen hohe Datenintegrität entscheidend ist.
Integration von fortschrittlicher Data Governance und feingranularer Zugriffskontrolle im Data Lakehouse.
- Einheitliches Richtlinien-Framework: OPA bietet ein leistungsfähiges, einheitliches Framework für die Steuerung des Zugriffs im gesamten Data Lakehouse und gewährleistet die konsistente Durchsetzung von Sicherheitsrichtlinien, Datenschutzbestimmungen und Compliance-Anforderungen.
- Deklarative Richtlinien als Code: Governance-Richtlinien erfolgen deklarativ mit Rego, der OPA-Syntaxsprache. Dieser Ansatz ermöglicht die Entwicklung klarer, verständlicher Richtlinien, die als Teil Ihrer CI/CD-Pipeline versionskontrolliert, überprüft und bereitgestellt werden können.
- Detaillierte Zugriffskontrolle: Feingranulare Kontrolle über den Datenzugriff und die Datenveränderung innerhalb der Data Lakehouse-Architektur.
- Skalierbar und hochleistungsfähig: OPA unterstützt auch große, komplexe Datenumgebungen und stellt sicher, dass Governance-Richtlinien effizient ausgewertet werden, ohne den Zugriff auf Daten oder die Anwendungsleistung zu beeinträchtigen.