


Both Lars and I have always had a special place in our heart for security throughout our consulting careers. It might have to do with being German, but most probably it was simply caused by being burned too often by redundant settings not matching, no common ciphers being found or any one of a thousand potential other security issues.
So when we started writing down the first designs and ideas for the Stackable Data Platform, our open source data distribution, one of the first principles we agreed upon was:
Security is a first class citizen, not an afterthought!
All by itself this is just a sentence with no real meaning of course, so in this blogpost what I’ll attempt to do is put our money where our mouth is and provide you with some details on what we came up with to fill that phrase with life.
Setting up security on a big data environment is a fairly involved task, even when supported by a management tool like Apache Ambari or Cloudera Manager.
You need to create a lot of TLS keys and certificates containing the correct hostnames, create service principals and keytabs in AD, set up a centralized tool to enforce ACLs like Apache Ranger or Apache Sentry, configure the tools to use this as well as configure authentication on the tools and set up ACLs to grant users access.
For a lot of these tasks there is simply no substitute, encryption without keys – won’t fly. What we’re doing is taking the pain out of generating and rolling out those keys as well as the ACL management.
Who is this article for
You don’t need to be an expert on security who is able to debate the pros and cons of individual encryption cipher suites for hours on end! You should however be familiar with security concepts like authentication and authorization in principle, as we won’t be covering everything from the ground up in this article.
Authentication
Authentication is the process of making sure that a user is who they say they are. This can be done in a huge number of ways:
- Username & Password
- TLS Certificates
- Kerberos Tickets
- Single Sign On Mechanism
- …
The list could go on and on.
The main issue with authentication is that no two tools from a typical Data tool stack support the same types of authentication in the same way. Every tool has its own understanding of how a user should be identified. And since this user identification needs to be supported by the client tools as well, it is not usually pluggable, which means that it is not easy to create custom implementations that allow adding new mechanisms.
So for authentication we are pretty much stuck with what the tools offer natively. But that is not a huge problem really, as the main thing we expect from the authentication step is a user id or a user principal that we can trust – and this will mostly just be a string. I will write more about how we implemented this in a future blog post.
Authorization
Right, now we have a user principal that we can trust, because it has been proven via a method that we consider secure – what now? This is where authorization comes into the picture, which takes this user principal and enforces a set of rules against it. In its simplest form this could just be
tom is allowed to read from table transactions
Or a bit more complex
tom is allowed to read the columns amount and date from the table transactions on rows where the field customer_id is equal to 123
Looks quite simple in principle, and if we were only talking about one isolated product it would actually not be terribly hard to do this. All tools from our stack support at least a simple ACL implementation, some of them even have fairly involved systems for this.
But this is exactly the problem that are solving in the security design for the Stackable Data Platform: It should not be 12 different authorization systems that all feel different, it should be one system that feels and works the same throughout the entire platform. In fact, throughout the design of our entire platform, this has always been our core tenet, to build something that feels as „the same“ as possible across multiple tools.
We are using the Open Policy Agent (OPA) as a central piece of the puzzle to achieve this goal. OPA is a tool which allows implementing complex authorization rules based on pretty much arbitrary input data. The language used to define these rules is called rego, which itself is based on Datalog.
The main benefit over existing solutions like Ranger that we see with Opa is, that all the logic can be kept in the rules themselves, which means that it becomes very easy to extend rulesets without any code being written and released.
Groups Lookup
Remember the example policies we looked at above? In practice you will only seldom find actual usernames in ACLs, what you’d usually want to do is something like the following:
users that are a member of the group reporting are allowed to read the columns amount and date from the table transactions on rows where the field customer_id is equal to 123
Which means that we need to come up with a way to look up groups for users from some form of directory service, most commonly LDAP or AD.
Often, the step of looking up groups for a user happens during the authentication step, and the retrieved information is then passed along with the user principal. This has the huge drawback of spreading the code to perform this lookup over multiple tools.
Ideally, what we wanted was to have the group lookup performed as part of the rule evaluation in OPA, which would allow us to do this once from a central component and reuse the same groups in rules for all products managed as part of our platform – which also allows for efficient caching.
OPA allows doing something like this with the concept of external data – the idea being that you can either embed external data that is required for authorization in the bundles that make up an OPA ruleset, or you can retrieve external data during evaluation of the rules.
Both have obvious benefits and drawbacks, embedding user-role assignments in the rules becomes cumbersome if there are a lot of users, a lot of groups and assignments change often. On the other hand, making a call to an external system for access requests is not a good option either. The good news here is, that this part of the design doesn’t have to be fixed, multiple implementations can easily be created as the need arises and live side by side in our code – the customer just needs to configure the best fit for their environment.
The following diagram shows the initial flow that we are implementing for group-based authorization:
So for our initial deployments, what we’d end up with is something roughly similar to the following:
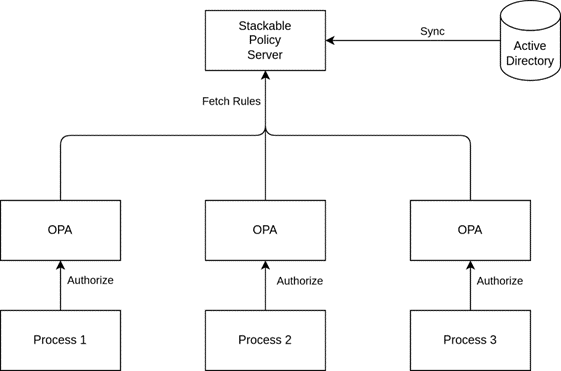
The Stackable Policy Server in this case is the central component that will be in charge of caching user to role mappings and other relevant data from a central directory service.
Authorization Rules
Everything we have looked at so far has always assumed that authorization rules are just there and can be applied to user requests. However, these rules don’t normally appear out of thin air, someone has to define them and, more importantly, hand them over to the system to enforce.
As we have seen in the OPA introductory section, regorules can become very complex and allow most of the authorization logic to be offloaded onto those rules. This has the benefit of simplifying the code that needs to run at the point of enforcement – at the downside of making the rules more complex.
Since this is not in line with our goal to make the plattform easy to use we will create product-specific abstractions that will allow our users to express their authorization needs in a much simpler way. Of course, as usual, this is an optional abstraction layer, if users feel they need more control, then the entire ruleset can be written manually as well.
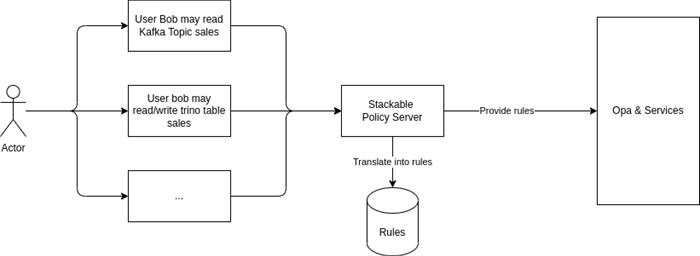
We will represent the abstraction layer as custom resources in Kubernetes, just like the definition of the platform itself, which has the huge benefit of being able to keep the definition of authorization rules in version control, alongside the architecture definition yaml files, where we feel they belong.
An additional benefit that this approach allows us to take is that we can very easily make rulesets composable, which allows the reuse of rules across environments for example.
Think of defining a rule on the dev environment and being able to migrate the same rule to test and prod after having tested it. No more finding typos in ACLs on prod after everything worked flawlessly on test … not that this ever happened to me of course!
The following diagram should give an idea of how we plan to make this work in principle. A lot of details are still up in the air as we are currently implementing this, but the idea in principle should become clear.
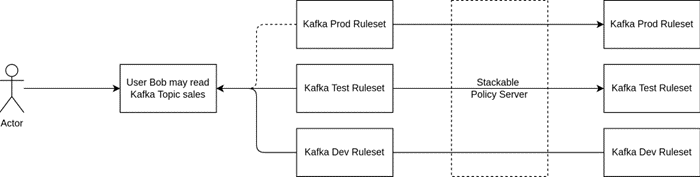
Wrapping Up
As a keen reader you may have noticed: None of what I wrote in this blog post is radically new or fundamentally different from what has been there before when securing clusters.
What we are doing with this design is to make the entire process more integrated and consistent across the board which in turn makes it easier to use for everyone. And systems that are easier to use and easy to audit are usually more secure. By integrating ACL definitions into the actual infrastructure definition and applying the “as-code” principle it becomes much easier to consistently manage access across multiple environments. Centralizing the user identity enrichment process cuts down on the number of applications that need to integrate with centralized directories.
If you have any comments or thoughts on this, then please do reach out, we love to discuss and are always open to new ideas!
And if you are interested in helping build all this: we are hiring!!!