


What possibilities does data mesh offer? What does it actually bring into my company and how can a data mesh project actually work? Everyone is already talking about data mesh as an alternative to the classic DWH or data lake. Together with Bitkom e. V., I was one of the authors of the white paper „Data Mesh – Finding and Using Data Potential“ and had the opportunity to look at these and many other questions about the topic. You can find my remarks on the topic of architecture here; you can download the entire guide from Bitkom e. V. free of charge. Please note: The guide is only available in German.
Download – Data Mesh – Find and use data potentials (German only)
Architecture
[…] Now that we have learned where the concept of the data mesh comes from, let’s get into the concrete architecture. The most important point here is that the Data Mesh is a „sociotechnological paradigm“. Behind this unwieldy word is the fact that a Data Mesh is not a purely technical solution, but a combination of data strategy, enterprise architecture and business organization. Technology plays a supporting but subordinate role. We have learned that the Data Mesh is a solution to bypass bottlenecks and increase or restore the speed of innovation within teams and organizations. A central building block of this architecture is therefore the consistent identification and removal of these bottlenecks by giving as much responsibility as possible to distributed teams, which nevertheless act according to centrally defined „guard rails“. This idea leads to a logical architecture based on four principles.
What possibilities does data mesh offer? What does it actually bring into my company and how can a data mesh project actually work? Everyone is already talking about data mesh as an alternative to the classic DWH or data lake. Together with Bitkom e. V., I was one of the authors of the white paper „Data Mesh – Finding and Using Data Potential“ and had the opportunity to look at these and many other questions about the topic. You can find my remarks on the topic of architecture here; you can download the entire guide from Bitkom e. V. free of charge.
Domain-oriented ownership
Responsibility for data does not lie with a central team, but is placed in the hands of the teams that work „closest“ to the data. These are often – but not always – the teams that also generate the data. This makes a data mesh fundamentally different from many data lake or data warehouse projects, where there are teams that receive, clean, structure and store all the data, but are not themselves experts in the particular domains from which the data comes. As a result, these teams often generate sub-optimal quality data sets and contribute to the inertia of the system. So the team that provides the data takes care of the entire lifecycle. Users only see the result – the data product. This brings us to the next principle.
Data as a Product
If „time is money,“ then data analytics is a disaster today. According to reviews documented in the literature, more than 80% of a data analytics project’s time budget today is spent on data preparation – not, say, algorithm development. This would turn the 80/20 Pareto principle, a cornerstone of business efficiency, on its head. The solution: treat data like products and apply proven approaches, like product management, to data. It’s about thinking of data as a product in its own right, not as a byproduct of another activity. A product includes everything necessary to make it available: Data, metadata, code, policies and, if necessary, infrastructure. The product must be autonomous and thus independently usable as well as provided by the offerer with a service level, which guarantees a reliable use. In other areas of software development, a principle called „shift-left“ is being applied more and more frequently. This means that tasks and responsibility move closer to the source. Probably the most prominent representative of this principle is the way software products are created today: DevOps increases speed, stability as well as improves coordination processes in software development. This is done by combining development („Development“) and operations („Operations“) in a single team. A comparable development can be found under the term DataOps for processes around data management and machine learning (MLOps) as well as security (DevSecOps) and also in the testing of software.
In the past, it was common for development departments to develop products and then hand them over to operations departments. DevOps breaks down this rigid distribution. The data mesh principle now extends this shift in responsibilities to the generated data, which is still very often managed by central teams. The data and its usability as a standalone product are brought back to the teams that produce the data and it is their responsibility to build a sensible data product. To embed this in the organization, new roles are helpful: „Domain Data Product Owner“ and „Data Product Developer“ who have responsibility for a data product. This principle is closely related to the previous one – Domain Ownership. While there it was about responsibilities and their decentralization, here it is about seeing data as a real product, like software artifacts before. This often leads to additional work in the respective teams which raises further questions. For example, who pays for the costs incurred. A product should meet these requirements: It must be discoverable, understandable, addressable, secure, interoperable & composable, trustworthy, natively accessible, and valuable on its own. Many of these requirements can be achieved or supported by technology, which brings us to the third principle.
Self Service Data Platform und Data Factories
Reading the previous points may raise concerns about a multiplication of knowledge, infrastructure and data. There are also concerns about skills shortages, as it sounds like each team needs enough experts to cover the entire lifecycle of a data product. However, this is not the case: a central infrastructure team should provide the necessary tools and standards in the form of a platform to enable non-specialist staff to carry out the necessary pipelines and processing steps themselves. This includes cross-cutting functionalities such as monitoring and logging, as well as common API standards and protocols. This „as-a-service“ idea should definitely be combined with an „as code“ approach: The ability to provide infrastructure as programme code, often within minutes, enables a new flexibility in the production of data products.
However, this is really only about making the platform and knowledge available. But not the concrete implementation – as mentioned, this lies with the specialised teams themselves.
Through this separation of tasks, it is not necessary to have tool-specific experts in each team; instead, trained users of these tools are sufficient. The goal should be to offer data mesh specific products across typical SaaS/IaaS/PaaS offerings. These can be ways to register data products in a central catalogue or automate data quality monitoring. Because data mesh is still relatively new, there are still some gaps in the available offerings. Some technical and non-technical topics, on the other hand, cannot be completely outsourced to the individual teams due to their nature, which brings us to the fourth and final principle.
An elegant approach to organising the creation of data products is to switch from manual labour to industrialised processes, just as with other products and consumer goods – the so-called data factories (Schlueter Langdon and Sikora 2020). In essence, it is about breaking down the conversion process from raw data to data products into core process steps and automating them.
Federated Computational Governance
There are some tasks that should always be centrally controlled. One example is the typical requirements of legal departments on the topic of data protection or sensitive data in general. (Data) security as well as automated tests and monitoring are also often part of this. For this, it is a good idea to set up a federated team consisting of members from all departments (domain/specialist departments, legal department, security, etc.). This team is responsible for defining central rules and, if necessary, setting guidelines for automatisms. The individual product teams, on the other hand, are responsible for their local governance, which includes, for example, authorisation rules on the data products. To dovetail these two components – local and global governance – it makes sense to build as much as possible on „as code“ approaches. In this case, „policy as code“ or „security as code“.
Summary
These four principles are meant to be used together – implemented individually they are not sufficient to meet the objectives. However, they do complement each other. Taken together, however, these four principles are sufficient. A comprehensive landscape for processing analytic data includes multiple components, which are performed by different roles in the organization. The logical architecture of a data mesh is exemplified as shown below:
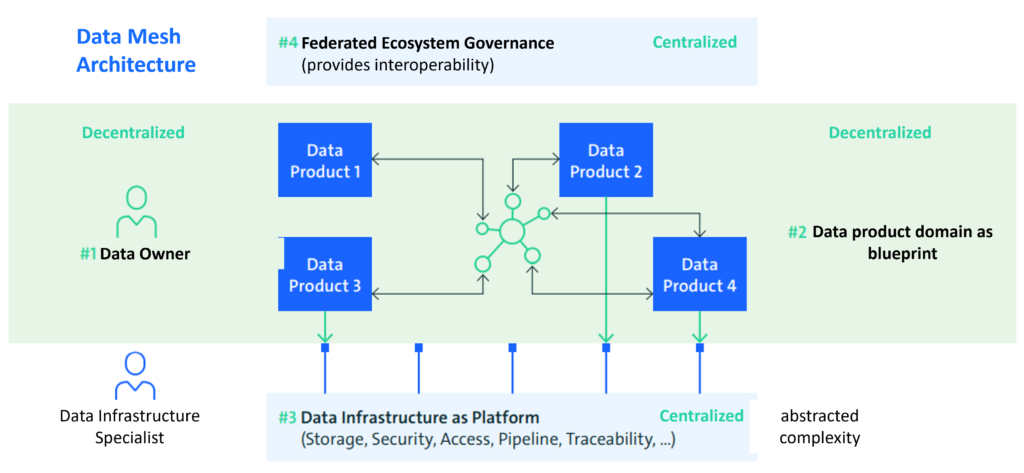
Implemented together, these four principles allow for decentralized processing and provisioning of data, which allows for faster response to changes or new requirements. Implementing a data mesh means allowing and implementing changes in the organization. There may be dissolution of existing teams, new tasks in existing teams, budget issues need to be clarified and much more. Also, it is important to remember that Data Meshes are still very new (2018) and there are still some unresolved issues and technical gaps.
Indeed, creating data products and making them available and cataloging them for quick retrieval/understanding will prevent data silos. Nonetheless, data products are also domain-specific in their own right and often do not allow interconnection with other data products. However, it is the combination of multiple data products that brings out the true potential of the data.
data. The reason that data products can be silos is that the data product owners often do not have domain-specific knowledge about the other data products. Consequently, there must be a central (cross-)team that now has knowledge of multiple data products and makes connections/transitions by creating new combined data products. Another option would be to create a higher-level domain model between the Data Products that creates a transfer/exchange of data from different domains, which again requires a central cross-team. So the decentralization of the Data Mesh has its limitations when it comes to defining higher-level commonalities/mapping of the Data Products, which need to be considered when implementing a Data Mesh.
You want to learn more about this topic? Then download the entire Bitkom guide free of charge here:
Download – Data Mesh – Find and use data potentials (German only)