


Apache Hive is a common feature in many Hadoop deployments and it’s not unusual to find Hadoop clusters where the primary use case boils down to SQL queries on structured data. Hive has strong roots in the Hadoop ecosystem and enough sharp edges to make migrating data and workloads to a new platform a significant challenge. At Stackable we know the Hadoop ecosystem and we’ve built Stackable Data Platform with maintaining, expanding and moving away from Hadoop in mind. Whatever your long term plan is for Hive, Stackable enables your vision with a DevOps oriented approach to deploying data infrastructure.
This is the first part of this blog post series in which we’ll explore some of the powerful features that Stackable Data Platform brings to both Apache Hive users and administrators. In future posts I’ll describe how to quickly and easily build your own Stackable sandbox environment for exploring how Hive and Trino interact and look at ways that you can use to expand, enrich and modernise your big data technologies.
A little bit about Trino
Central to Stackable’s Hive strategy is Trino, the distributed and scalable SQL query engine chosen to form part of Stackable Data Platform. I’ll admit that quite a few of us here have become big Trino fans and for good reason. What’s really special about Trino is that it’s a database polyglot of sorts, being able to talk to many different data sources including Apache Hive. Trino does not come with a built-in metadata catalog and Stackable Data Platform provides Hive metastore to this end. The advantage Stackable brings is joining these components together in a single platform, making it easier to deploy your data stacks quickly and reliably.
Trino is a massively parallel processing (MPP) database engine with a modular approach to data sources. Trino connectors are available for a range of data sources, including NoSQL and traditional relational databases. Most importantly for Hive users there is a Trino connector for the Hive metastore. It operates in much the same way that Apache Impala does, using the Hive metadata from the metastore and direct access to the underlying storage to run queries using its own SQL engine. Provide the Trino Hive connector with your Hive configuration you’re able to access your existing Hive tables. Compatibility with the popular Hive table formats is good, with Trino supporting the most commonly used file types (e.g. ORC, Parquet) as well as Hive ACID tables.
Putting things together
This diagram below shows a typical Hadoop deployment alongside a similar Stackable Data Platform cluster. Trino is able to connect to the Hadoop cluster’s Hive metastore and read the data directly from HDFS. The Trino coordinator will read and cache Hive metadata and plan queries in the same way that Hive does. Trino does not rely on a separate execution manager like YARN and instead uses worker nodes to run the query, analogous to the Impala daemon running in executor mode.
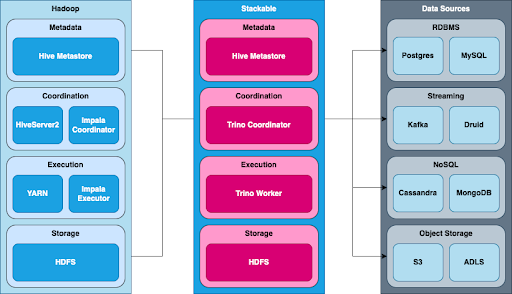
Stackable Data Platform gives you much more than just a Kubernetes operator for Trino and provides everything you need to build an alternative to your current data stack. If you want to stick with Hadoop you have the capability to deploy a HDFS cluster for storage but Stackable will happily connect other HDFS clusters and use their Hive metastore to access existing Hive tables. Being able to connect to external data sources both as a source and a sink is where one of the key strengths of Trino lies. The wide range of connectors to different data platforms means not only can Trino query and store data in many locations and formats but also join data between those sources.
Deploying Stackable means that federated queries and simple SQL based ELT from external data sources like relational now become possible, a feature that Hive lacks natively. From the perspective of Hive migration this is a very powerful tool since Stackable and Trino can provide a Rosetta stone to translate between heterogeneous data storage and processing systems that requires no change to the source system. You can create and copy tables on your new data platform using CTAS statements (where supported by the specific Trino operator) or use Trino as a bridge to getting your data onto cloud storage.
Translating HQL into SQL
Hive uses its own dialect of SQL named Hive Query language or HQL that differs from the ANSI standard. If you’re planning to move away from Hive then this presents something of a challenge since there’s a good chance that your existing queries will need some modification. Some things to watch out for include differences around access to arrays and their elements, expanding arrays and maps, delimiting identifiers, string concatenation, type casts, filter queries and overwriting existing data. That sounds like a lot, but the cost of moving away from non-standard SQL dialects is hopefully one you’ll only need to pay once.
By connecting Trino to an existing Hive cluster you can test the compatibility of your queries and compare the results between Trino and Hive using exactly the same tables in each case. Most folks will no doubt gain peace of mind from being able to demonstrate that they see the same results on the new platform compared to their existing one, all without having to move any data. Trino provides a useful Hive migration guide covering the most common challenges.
There is of course the need to convert the Hive DDL statements you use such as CREATE TABLE and CREATE VIEW to make them compatible with Trino as well as your queries. Again Trino is a powerful translation tool that helps us do this. Once you’ve connected Trino to your Hive metastore you can run SHOW CREATE statements to produce Trino-friendly definitions for your tables and views. This also works for many of the Trino connectors giving you a lingua franca to exchange metadata between otherwise incompatible systems. These seemingly minor changes can be a pain to deal with manually, but the example below shows a Hive DDL statement and the corresponding SQL DDL generated by Trino.
| Hive HQL DDL Statement | Trino SQL DDL Statement |
CREATE TABLE store_returns | CREATE TABLE hivehdfs.tpcds.store_returns ( |
Stackable enables your Big Data journey
When you deploy a Stackable cluster you can choose exactly which components to use to build your ideal data stack. In the spirit of open source one of our aims was always to build a platform that plays well with others. Being able to connect to a wide variety of different data sources is a crucial part of this strategy. Stackable can form the hub of your data platform and link your data sources together just as well as it can build a cloud-scale data warehouse. Leveraging everything as code paradigm, DevOps and Kubernetes means we’ve built a fast, flexible and consistent platform to suit the needs of modern data orientated business.
This has been a very high-level view of how Stackable and Trino can become part of your data platform journey. For the more technically inclined, the next blog post in this series will dive into connecting Trino to two Hive metastores to simulate the migration from Hadoop and Hive to Stackable. We’ll provide all the code you need to build your own Stackable cluster and try it out for yourself. At Stackable we’ve always aimed to make open source software more accessible and easier to deploy, so strap in and get ready to launch into your next adventure in Big Data!