


TL;DR
In this blog post, I describe a benchmarking exercise we conducted to compare the performance impact of running HBase and HDFS on Kubernetes versus running them on bare-metal. The blog post explains the challenges of running stateful workloads on Kubernetes and the questions the team set out to answer through the benchmarking exercise. The workload used for the benchmarking was Yahoo’s cloud serving benchmark, and the benchmark was run on similar hardware configurations in a variety of cloud environments. The results of the benchmarking exercise are presented and discussed. Our benchmark tests showed that Kubernetes didn’t introduce any significant performance penalties compared to bare-metal setups.
Introduction
Here at Stackable we are building a modern data platform to easily define and operate data processing architectures. One part of the claim of being a „modern“ platform is that all services are deployed on Kubernetes, which ensures the platform can run effortlessly on a lot of cloud and on-premise environments.
Kubernetes is a fabulous system for deploying and scaling workloads but it does require a few compromises from its users, especially when running workloads that keep lots of state – like big data workloads. This is largely due to the initial project goals that were defined when Kubernetes was started, which were mainly to allow easy scaling and managing of stateless workloads, or workloads with limited amounts of shared state – such as a website that needs to be able to accommodate huge load spikes. To enable this, two core assumptions were that Kubernetes needed to be able to control network traffic to a large extent as well as mount remote storage into workloads.
Due to these additional layers of indirection, an often asked question is whether Kubernetes introduces a significant performance penalty when compared to running services on „bare-metal“.
NOTE: bare-metal in the context of this blog post does not refer to whether or not the servers are virtual machines or actual metal servers but is used as a term to signify natively running software on the operating system, without containers and kubernetes as extra layers.
We have had an item on our todo list for some time to run some proper benchmarks and compare the impact that Kubernetes has on the tools from our stack, but somehow we could never get around to it: something else was always more pressing and needed doing first. A few weeks ago however, a potential customer asked for HBase benchmarks. This specific use case is very latency sensitive, as it is in the critical path for authorizing financial transactions – so they wanted to understand, how much, if any, performance penalty moving from a bare-metal to a Kubernetes based architecture would add in this case.
In this blog post I will describe the benchmarks we ran, what questions we originally set out to answer, which questions we stumbled across along the way and – most importantly – the results we got!
Setup
Main Objective
The main question we wanted to answer in this benchmark was, what is the overall performance impact of running HBase and HDFS on Kubernetes?
There has been a lot of speculation about whether data locality (or rather the lack thereof), overlay networks and all the other abstractions Kubernetes introduces could adversely affect performance. But very few actual numbers have been published as far as we could find.
What we therefore set out to do was run an HBase workload on the same hardware – once in a bare-metal setup, once with the Stackable Data Platform (SDP) on Kubernetes.
Workload
Since running the customer’s actual workload was not possible for a variety of reasons, we needed to come up with a benchmark workload that is somewhat similar in its query pattern and data volume. After a bit of debate we settled on Yahoo’s venerable cloud serving benchmark, which has been around for more than a decade. The benchmark defines a couple of workloads with different query profiles, read heavy, update heavy, … for a full description of the individual workloads please refer to the diagram in the „Numbers“ section below.
To resemble the customer’s use case as much as possible, the benchmark had to be read-heavy, with many clients (high concurrency) on a medium-sized dataset:
- 3 Million records
- 10 columns
- 100 byte field size
YCSB then has several workloads defined that you can run against this generated dataset, which represent different patterns of data access. If you are interested in the exact definitions of these workloads, I encourage you to head over to the YCSB Github repository and check out the source files. The table below gives an overview of the workloads available in YCSB:
| Workload | Focus | Application example |
|---|---|---|
| Workload A | Update heavy workload | Session store recording recent actions |
| Workload B | Read mostly workload | photo tagging; add a tag is an update, but most operations are to read tags |
| Workload C | Read only workload | user profile cache, where profiles are constructed elsewhere (e.g., Hadoop) |
| Workload D | Read latest workload | user status updates; people want to read the latest |
| Workload E | Short ranges | threaded conversations, where each scan is for the posts in a given thread (assumed to be clustered by thread id) |
| Workload F | Read-modify-write workload | user database, where user records are read and modified by the user or to record user activity. |
Benchmark Environments
The baseline was provided by the customer after running the benchmark workloads on a ten node cluster of physical machines in their local data center. As stated above however the main objective was to compare like-for-like, i.e. on similar hardware. Since it was not possible to install SDP on the customer’s data center, we instead looked at the major cloud vendors for alternatives that could get us as close as possible to the baseline hardware specifications.
The main three Amazon AWS, Google Cloud and Microsoft Azure all offer managed Kubernetes services, so we created similar sized clusters there to run the benchmark workloads.
The main difference between these clusters and the on-prem reference cluster however, was the storage. The physical machines had 12 directly attached disks each, whereas the cloud offers mostly network attached storage. This has the disadvantage that multiple volumes share the same bandwidth when mounted on the same machine. We’d therefore expect to see significantly reduced storage throughput when comparing the two setups.
We ran tests on pretty much all clouds and in a lot of cluster configurations. This was done mainly to get a feeling for the subtle (and not so subtle) differences between the cloud vendors, and what settings influence the results in what way.
After a lot of testing we finally settled on Google’s Kubernetes Engine for the actual comparison, because this gave us the best overall results.
To achieve a like-for-like comparison we compared two similar clusters, one provisioned by Googles Kubernetes Engine, the other one using bare VMs from Google’s Compute Engine, on which we manually installed HDFS and HBase without any container or virtualization technology.
On the GKE cluster we provisioned the Stackable Data Platform and deployed HDFS and HBase with the same configuration settings.
| Spec | Value |
|---|---|
| Nodes | 16 |
| Cores | 8 |
| Memory | 32 GB |
| Disks | 1 (remote) |
We didn’t use more than one disk, as multiple disks attached to the same VM share the underlying network bandwidth according to the documentation, so this wouldn’t bring any significant performance benefits.
This gave us the closest approximation to the hardware that we would expect to be available in a cloud environment without actually having the physical servers under our control.
Results
I will split this section into two, one containing the actual numbers that we saw in direct relation to our main question – arguably the result of this benchmark.
However, while getting at those numbers, there were a few learnings about Kubernetes and the Cloud that we found to be very interesting and which I’d like to share as well.
Learnings
Latency can vary wildly – and has a huge impact in low latency scenarios
Initially we had very disappointing results when running the benchmark: timings were upwards of quadruple the reference times we had been given. When looking at this more closely though, it quickly became obvious that this was easy to explain simply by looking at network round-trip times. Take for example the average read time for a single value, which was sub-millisecond in the reference benchmark. In cloud environments we saw ping times between 2 and 4 milliseconds between the individual nodes, so just a single network round trip would already cause higher times than what we were shooting for. And since we need several round trips for an answer, this quickly adds up.
We did play around with various networking implementations and cloud settings to try to improve these numbers as much as possible.
For our specific scenario, the solution turned out to be „compact placement“, a beta feature on the Google Cloud that tries to allocate VMs close to each other in the Kubernetes cluster. This turned out to significantly lower network latency during the tests.
The cloud is not predictable
We repeated the benchmarks frequently, with the same settings on the same config, on the same cloud setup, and the results varied quite a bit over time.
Setting up a cluster is not idempotent: using the same commands and configuration on a Thursday morning to create a cluster and run the same benchmarks as was done the day before was no guarantee that the environment – and thus, the results – would be identical.
We suspect that this is down to where machines are allocated, who else is using the hardware, what’s happening in the network neighbourhood etc.
This can most probably be influenced to a certain degree by cloud specific settings and products like sole-tenant nodes and similar concepts on other clouds. However, for the purpose of this benchmark we did not investigate this any further.
The cloud is not predictable (part 2)
As mentioned in the section on latency above we relied on the „compact placement“ feature of the Google Cloud to consistently provide low network latency. A side effect of this was that sometimes provisioning a cluster failed because not enough nodes were available close to each other in the selected region. This problem seems to affect Compute VMs to a far greater degree than GKE clusters.
The cloud is not predictable (part 3)
When I tried provisioning demo environments late the evening before the big presentation of our benchmark results I was unable to do so due to an incident with the key storage of our cloud provider that caused provisioning to fail. Since the meeting was scheduled for 9 o’clock the next morning this caused a bit of anxiety and a late night wake up call to check on the state of the incident and restart provisioning so the cluster was available and running on time.
Numbers
Ok, let’s get to what you have all been waiting for, the results of the benchmark.
Below you will find a table that shows the results as measured by YCSB for both clusters next to each other. To make it a bit easier on the eyes we have rounded all times to the nearest millisecond. We have also introduced a color scheme that shows results presented in a way that reflects the specified goal, which of course was to prove that SDP on Kubernetes can be as fast as a bare-metal deployment.
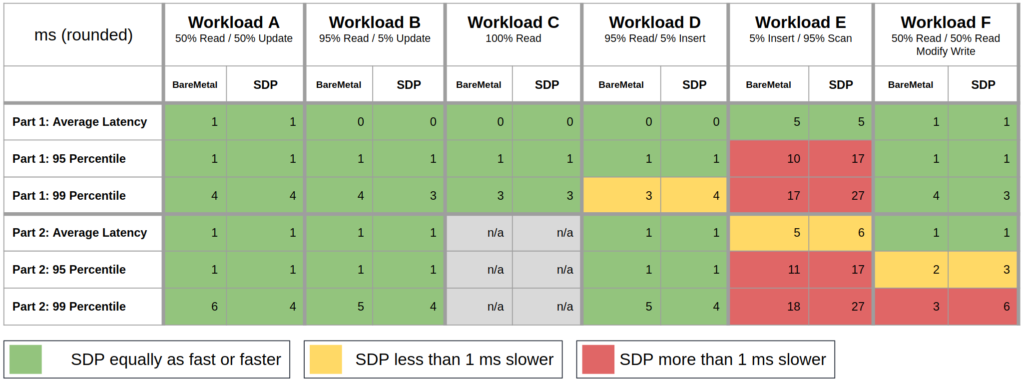
This table clearly shows that the numbers are fairly close across the board, with the sole exception of workload E, which is an insert & scan-heavy workload. The assumption for this workload is that, due to the large volumes of data that have to be moved during a scan operation, the storage indirection that Kubernetes introduces has a more pronounced effect on throughput.
The main difference between the two clusters that we think may have led to this effect was that for Kubernetes we had to rely on PersistentVolumes, whereas for the virtual machines we attached disks directly to them.
Conclusion
In conclusion, we found that Kubernetes is a viable platform for running big data workloads like HBase and HDFS. Our benchmark tests showed that Kubernetes didn’t introduce any significant performance penalties compared to bare-metal setups. The Stackable Data Plattform on Kubernetes performed very well across the cloud vendors tested.